Welcome to Neilpang's Blog!
记录生活,分享知识,传播乐趣-
排除不受信任的根证书列表:cnnic, alibaba
今天心血来潮, 检查一下我的根证书列表:
certmgr.msc排除了一些垃圾流氓证书到不受信任的列表, 以下是我的列表:

其中 'CNNIC ROOT' 自不必多说.
其中有三个证书值得一说:
- 首先说说前两个, 一个是 'Alibaba.com Corporation Root CA', 另一个是: 'ALIPAY_ROOT'. 作为一个第三方的电子商务公司, 我实在想不通他为什么要在我的机器里面装入 根证书. 而且可以看到这两个根证书的用途都是 "所有". 就是权限最大的根证书. 不光可以做普通证书做的事,比如签名,加密,时间戳等等. 甚至还能签发次级CA.
首先, alibaba 网站上使用的证书都是 来自第三方的verisign的. 这没有任何问题. 那他还要给我装权限如此之高的根证书的目的是什么? 除了耍流氓还有什么解释. 你当用户的电脑是韭菜园子吗? 你视用户的安全如空气吗? 有一天要逼我在虚拟机中使用 支付宝吗? 去年买了个包. 流氓.
- 再说说另一个, 就是图中的'ROOTCA', 名字看起来很唬人. 以为是正规的根证书.
但是我们点开详细信息看看:
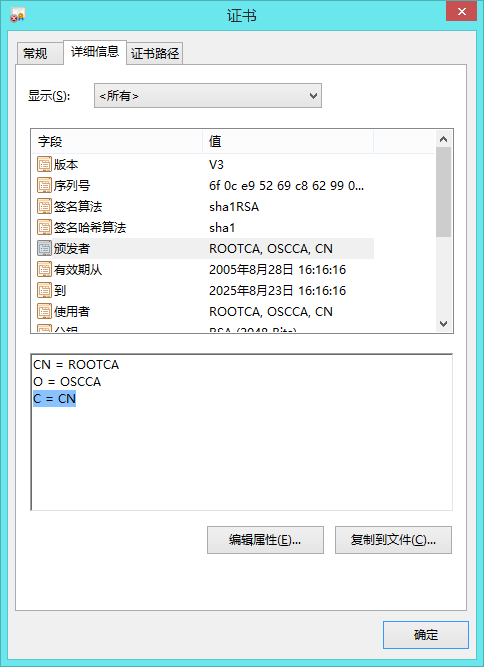
发现他的 C=CN
原来, 这货和 CNNIC 是一路货色.果断禁用之.
最后分享一下禁用方法.
在"受信任的根证书颁发机构"中找到他们之后, 不能直接删除, 删除之后,有些会自动安装比如alibaba, 有些会通过windows自动更新重新装入, 比如CNNICroot. 正确的做法是, 用鼠标把他们拖到下面的 "不信任的证书" 分支里面.
这样就算重新安装了, 他们仍然是不受信的.我很喜欢淘宝, alibaba, 支付宝, 也是马云的粉丝. 但是,无论是谁,耍流氓就不行. 让流氓证书滚粗.
-
php 操作数组 add_assoc_string 导致 崩溃
使用php内核的方法 操作数组时 导致 php崩溃。
int add_assoc_string ( zval* $arg, char* $key, char* $str, int $duplicate )*http://php.undmedlibrary.org/manual/en/zend-api.add-assoc-string.php
原因是:第三个参数, 添加的字符串不能使NULL。
添加之前要先判。 如果是NULL, 应该使用专门加NULL的api:
int add_assoc_null ( zval* $arg, char* $key )http://php.undmedlibrary.org/manual/en/zend-api.add-assoc-null.php
-
解决:fatal error C1902: Program database manager mismatch; please check your installation
重装系统后,VS2008编译出现错误。
fatal error C1902: Program database manager mismatch; please check your installation可能是多版本共存引起的问题。
找到这篇文章:http://wordrump.com/how-to-fix-the-error-fatal-error-c1902-program-database-manager-mismatch-please-check-your-installation/
简单暴力, copy 这三个文件:
mspdb80.dll mspdbcore.dll mspdbsrv.exe从
C:\Program Files (x86)\Microsoft Visual Studio 9.0\Common7\IDE
到
c:\windows解决。
-
添加Access-Control-Allow-Origin主机头, 授权资源跨站访问
Access-Control-Allow-Origin 是html5 添加的新功能, chrome貌似前几天更新之后支持了这一特性.
基本上, 这是一个http的header, 用在返回资源的时候, 指定这个资源可以被哪些网域跨站访问.
比方说, 你的图片都放在 res.byneil.com 这个域下, 如果在返回的头中没有设置 Access-Control-Allow-Origin, 那么别的域是不能外链你的图片的.
当然这要取决于浏览器的实现是否遵守规范. 因为chrome最近的升级开始检查这个头了, 所以导致一些网站资源加载不进来.
解决方法就是 在资源的头中 加入 Access-Control-Allow-Origin 指定你授权的域. 我这里无所谓,就指定星号 * , 任何域都可以访问我的资源.
Access-Control-Allow-Origin: *具体操作方法, 就是在nginx的conf文件中加入以下内容:
location / { add_header Access-Control-Allow-Origin *; }这样就好了.
-
linux 清理磁盘,查找大文件
查看磁盘的占用:
df -hneil@dedia:~$ df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 139G 37G 96G 28% / none 4.0K 0 4.0K 0% /sys/fs/cgroup udev 983M 4.0K 983M 1% /dev tmpfs 199M 500K 198M 1% /run none 5.0M 0 5.0M 0% /run/lock none 992M 0 992M 0% /run/shm none 100M 0 100M 0% /run/user /dev/sda1 180M 34M 134M 20% /boot如果需要清理磁盘的话, 用 find 命令找出大文件,然后酌情删除:
find / -size +100M -exec ls -lh {} \;这就是要查找磁盘上大于100m 的文件.
参考:
http://lovesoo.org/linux-system-to-find-clean-the-disk-file.html
-
安装 jekyll 记录
* 安装 ruby
apt-get install ruby1.9.1* 一定要再安装 ruby dev
apt-get install ruby1.9.1-dev* 安装 jekyll
gem install jekyll查看是否安装成功:
jekyll --version- 如果出现错误,找不到javascript 运行时, 类似:
execJs: 'Could not find a JavaScript runtime' but execjs AND therubyracer are in Gemfile请安装 nodejs:
wget wget http://nodejs.org/dist/v0.10.31/node-v0.10.31.tar.gz tar xf node-v0.10.31.tar.gz cd node-v0.10.31 ./configure make && make install* 如果一切顺利的话, 顺便再把markdown也装上吧:
gem install rdiscount