Welcome to Neilpang's Blog!
记录生活,分享知识,传播乐趣-
ssh 使用public key 免密码登录
第一步,生成自己公钥, 私钥
1: ssh-keygen -t rsa2:3: root@yjlml:~# ssh-keygen -t rsa4: Generating public/private rsa key pair.
5: Enter file in which to save the key (/root/.ssh/id_rsa):
6: Enter passphrase (empty for no passphrase):
7: Enter same passphrase again:8: Your identification has been saved in /root/.ssh/id_rsa.
9: Your public key has been saved in /root/.ssh/id_rsa.pub.
10: The key fingerprint is:
11: 3e:6e:d9:12:7c:f8:6f:18:f6:65:cb:6e:16:4f:83:43 root@yjlml12: The key's randomart image is:
13: +--[ RSA 2048]----+14: | |15: | |16: | |17: | E |18: | .S. . . |19: | .+ + o+..|20: | oB + +.=.|21: | .+.+ o = .|22: | ... o.+. |23: +-----------------+中间连续按几次回车, 使用默认文件名, 并不输入密码。
二, 把你的公钥,拷贝到远程机器的 “~/.ssh/authorized_keys” 文件中。
刚才生成的公钥在: ~/.ssh/id_rsa.pub, 里面是文本,直接复制出来,粘贴到远程的“~/.ssh/authorized_keys” 文件中即可。 如果没有这个文件,自己新建一个。
这个文件可以保存多个公钥,只需要连续放在里面就可以了。
拷贝的方法有很多。自己想办法。
拷贝完成之后,重启一下ssh服务。
service ssh restart
然后测试是否成功:
1: root@yjlml:~# ssh root@190.***.***.*** -p 22 ls这里故意指定了一个端口22, 其实可以省略的。如果你的ssh端口不是22可以这样指定。
这句话是在远程执行一个 命令 ls, 看能不能执行成功。
如果能看到ls的结果。那就是成功了。
三, 错误处理
如果访问不成功,请检查远程机器的 “/etc/ssh/sshd_config ”文件:
找到其中的这一段。
6: RSAAuthentication yes7: PubkeyAuthentication yes8: #AuthorizedKeysFile %h/.ssh/authorized_keys
注意,必须开启 公钥认证, 检查公钥文件。
改完之后,重启远程ssh服务: service ssh restart
-
翻译,NTLM和频道绑定哈希(EPA)
为了过NTLM 的EPA认证, 参考了这篇文章,现在翻译过来,备查。
如果你知道NTLM,并且需要过EPA, 那么这篇文章一定是你最想知道的。
原文地址:
NTLM and Channel Binding Hash (aka Extended Protection for Authentication) - Microsoft Open Spec
=======================
Extended Protection for Authnetication (EPA) was introduced in Windows 7/WS2008R2 to thwart reflection attacks. This blog describes the changes in the implementation of NTLM Authentication that are needed to successfully authenticate to servers that have EPA enabled. Windows 7/WS 2008R2 and Windows 8/ WS2012 have EPA enabled out of the box.
认证的扩展保护(EPA) 在Windows7/WS2008R2 中引进, 用来对抗反射攻击. 本文介绍了要通过服务器端EPA认证,NTLM实现上的必要的改变. Windows7/WS2008R2 和Windows8/WS2012默认开启了EPA.
You can read the details about EPA here http://technet.microsoft.com/en-us/security/advisory/973811
这里有EPA进一步的细节.
The concept in EPA is that authentication packets should be bound to the secure channel on which they are transmitted. This concept is not new and is known as channel binding (RFC 5056). RFC 5929 describes channel bindings for TLS that Winodws uses to bind the secure channel to authentication. Please note that EPA also uses Service Pricipal Name (SPN) but it is not used for TLS and we will not discuss it here.
EPA的概念是认证的数据包应该绑定到传输它的安全频道上. 这个概念并不是全新的, 它就是众所周知的频道绑定(RFC5056). RFC5929描述了描述了Tls的频道绑定, Windows用它绑定安全频道到认证. 请注意, EPA同样也使用了服务主体名称(SPN), 但是这没有被用于TLS, 我们在这不讨论它.
Let's take an example of HTTPS, a protocol that uses TLS. Once a secure channel is established and cipher change has happened, HTTP traffic starts flowing. In this example, we are only considering services that require authentication. NTLM or Kerberos will be used if you are using Windows authentication. You are most likely to use NTLM since the whole point of using HTTP and TLS is to allow clients to connect over internet (In Windows 8, Kerberos can be used on the internet but we will concentrate on NTLM here). In case of Windows client, these are the steps that are taken to incorporate channel binding in the authentication process after secure channel has been established:
我们看看HTTPS协议, 它使用了TLS. 一旦安全频道建立,并且密码交换完成, HTTP就开始传输. 在这个例子中, 我们只关心需要认证的服务. 如果你正在使用Wndows认证的话, NTLM或者Kerberos将会被应用.你很可能会使用NTLM, 因为在TLS上使用HTTP的全部原因就是允许客户端通过Internet连接. (在Windows8中, Kerberos也能引用于internet, 但是我们仍然集中在NTLM上.) 对于Windows客户端, 在安全频道建立之后, 认证过程中, 构成频道绑定的步骤如下:
1. The hashing algorithm for the signature in the certificate is identified, if present.
如果存在, 证书签名的哈希算法先被识别出来.
2. SSPI calculates a hash (almost always SHA256 hash, see below for details/exceptions) of the certificate, appends other data relevent to the type of channel bindings and returns it to the application.
SSPI 计算证书的哈希值(通常是SHA256, 后面会有细节和例外), 加上频道绑定类型的相关数据, 然后返回给应用程序.
4. SSPI calculates the MD5 hash of channel bindings and uses it in the calculation of NTLM version 2 response.
SSPI 计算频道绑定的MD5哈希值, 用于计算 NTLM version 2 的回复
5. When server recives authenticate message, it queries SSPI for channel bindings. SSPI does exactly the same thing as on the client side and returns the data to the service. The service includes it in the call to method Accept Security Context (ASC)
当服务器接收到认证消息之后, 它像SSPI查询频道绑定. SSPI 进行域客户端完全一样的操作, 并把数据返回给服务. 服务端在 接受安全上下文(ASC)的调用中包含这个数据.
6. In the process of verifying authenticate message, SSPI also takes into account the channel bindings. It calculates the MD5 hash of the channel bindings that were provided by the application (service) and compares it to the one sent by the client. If they match and rest of the authentication requirements are met, authentication is successful.
在校验的认证消息的过程中, SSPI同样要考虑频道绑定. 它会计算应用(服务)提供的频道绑定的MD5值, 并且和客户端发送过来的值进行对比. 如果匹配, 并且人权衡的其他条件满足, 则认证成功.
I'll now elaborate on each of the step listed above with a concrete example of RPC-over-HTTP traffic. The TLS network traffic is encrypted and I used Network Monitor expert Network Monitor Decryption Expert (NmDecrypt) to decrypt it. The decrypted network trace is attached to this blog.
下面使用一个具体的 RPC-over-HTTP 的传输来具体描述上面的每一步. Tls的网络传输都是加密的, 我使用了 Network Monitor expert Network Monitor Decryption Expert (NmDecrypt) 来解密. 解密的网络跟踪在帖子的附件中.
If you open the network trace in Network Monitor, you'll see that in frame 16 server sends a certificate to client, as below (copied and pasted from the trace):
打开 网络跟踪日志, 你会发现在第16帧, 服务端发送了一个证书给客户端, 如下:
......
After secure channel is established and cipher change has taken place, HTTP traffic starts flowing.
在安全频道建立之后,并且密码交换完成, HTTP传输就开始了.
In this example, HTTP is being used as a transport for RPC and RPC server requires authentication. For authentication, the client application first calculates the channel binding by using the following process(in Windows this is done by SSPI but that is not important in this discussion ). This process is based on RFC 5929.
在这个例子中, HTTP用来传输RPC, 并且RPC服务器要求认证. 对于认证, 客户端首先计算频道绑定, 过程如下(在Windows中, 由SSPI完成, 但这不重要): 这个过程基于RFC5929.
1. The channel binding type for this example is "tls-server-end-point" since a certificate is used in handshake (RFC5929).
频道绑定类型在本例中是 "tls-server-end-point", 因为在握手时使用了证书.
2. The client calculates a hash of the certificate. The hashing algorithm is SHA-256, unless all of the following conditions are met, in which case the signature algorithm in the certificate will be used.
客户端计算证书的哈希值. 哈希算法是SHA256, 除非下面的条件都满足, 此时将会使用证书的签名算法.
A certificate signature algorithm exist
证书签名算法存在
The algorithm is only implemented in CNG (ALG_ID is CALG_OID_INFO_CNG_ONLY)
(证书签名)算法只在CNG中实现(ALG_ID 为 CALG_OID_INFO_CNG_ONLY).
The algorithm has a corresponding CNG algorithm identifier string (pwszCNGAlgid)
(证书签名)算法有相应的CNG算法标示字符串(pwszCNGAlgid)
The algorithm is not SHA1
算法不是SHA1
The algorithm is not MD5
算法不是MD5
3. The SHA-256 hash of the above certificate is: ea 05 fe fe cc 6b 0b d5 71 db bc 5b aa 3e d4 53 86 d0 44 68 35 f7 b7 4c 85 62 1b 99 83 47 5f 95
上面证书的SHA-256哈希值是: ea 05 fe fe cc 6b 0b d5 71 db bc 5b aa 3e d4 53 86 d0 44 68 35 f7 b7 4c 85 62 1b 99 83 47 5f 95
4. The Channel binding unique prefix (RFC5929) "tls-server-end-point" is prefixed to the hash above (with a colon), resulting in
74 6c 73 2d 73 65 72 76 65 72 2d 65 6e 64 2d 70 6f 69 6e 74 3a ea 05 fe fe cc 6b 0b d5 71 db bc 5b aa 3e d4 53 86 d0 44 68 35 f7 b7 4c 85 62 1b 99 83 47 5f 95
频道绑定前缀"tls-server-end-point"被附加到这个hash值得前面(冒号分隔):
74 6c 73 2d 73 65 72 76 65 72 2d 65 6e 64 2d 70 6f 69 6e 74 3a ea 05 fe fe cc 6b 0b d5 71 db bc 5b aa 3e d4 53 86 d0 44 68 35 f7 b7 4c 85 62 1b 99 83 47 5f 95
5. The above value is inserted as the value of application_data field of gss_channel_bindings_struct structure, as pointed out by MS-NLMP section 2.2.2.1
上面这个值插入到 gss_channel_bindings_struct 结构的 application_data 字段 . 这个字段在 MS-NLMP section 2.2.2.1 描述.
6. Windows always sets the other fields of gss_channel_bindings_struct as zeros (SEC_CHANNEL_BINDINGS
structure). The resulting gss_channel_bindings_struct is as follows (little endian format):
Windows 总是将 gss_channel_bindings_struct 机构的其他字段设为 0. gss_channel_bindings_struct 结构的结果如下(小端格式):
00 00 00 00 //initiator_addtype
00 00 00 00 //initiator_address length
00 00 00 00 //initiator_address pointer
00 00 00 00 //acceptor_addrtype
00 00 00 00 //acceptor_address length
00 00 00 00 //acceptor_address pointer
35 00 00 00 //application_data length (53 bytes)
20 00 00 00 //application_data pointer (32 bytes from start of this structure)
74 6c 73 2d //application data, as calculated above
73 65 72 76
65 72 2d 65
6e 64 2d 70
6f 69 6e 74
3a ea 05 fe
fe cc 6b 0b
d5 71 db bc
5b aa 3e d4
53 86 d0 44
68 35 f7 b7
4c 85 62 1b
99 83 47 5f
95
After calculating channel binding, the client application starts authentication and include channel binding as part of authentication. In case of NTLM, the gss_channel_bindings_struct is called ClientChannelBindingUnhashed (MS-NLMP section 3.1.1.2). As explained in MS-NLMP section 3.1.5.1.2, the client adds an AV_PAIR structure and set the AvId field to MsvAvChannelBindings and the Value field to MD5(ClientChannelBindingsUnhashed). The MD5 hash of the above gss_channel_bindings_struct turns out to be:
频道绑定完成之后, 客户端开始认证, 将频道绑定作为认证的一部分包含进来. 对于NTLM, gss_channel_bindings_struct 结构 被叫做: ClientChannelBindingUnhashed (MS-NLMP section 3.1.1.2). 正如 MS-NLMP section 3.1.5.1.2, 中所介绍的, 客户端添加一个AV_PAIR 结构, AvId字段设为 MsvAvChannelBindings, 而Value字段设为 MD5(ClientChannelBindingsUnhashed). 上面的gss_channel_bindings_struct 结构的MD5值如下:
65 86 E9 9D 81 C2 FC 98 4E 47 17 2F D4 DD 03 10This value is part of the AUTHENTICATE_MESSAGE in frame 27 in the network trace attached (in the network trace it is shown in Base64 encoding as 45 41 42 6C 68 75 6D 64 67 63 4C 38 6D 45 35 48 46 79 2F 55 33 51 4D 51 with AvLen) .
这个值作为AUTHENTICATE_MESSAGE 认证消息的一部分, 在附件的第27帧(附件中显示为Base64的编码值: 45 41 42 6C 68 75 6D 64 67 63 4C 38 6D 45 35 48 46 79 2F 55 33 51 4D 51 包含 AvLen ).
When server receives the AUTHENTICATE_MESSAGE, in addition to the regular authentication processing, it also verifies the channel binding hash by calculating it the same way the client did. If the channel binding hash does not match, the authentication will not be successful. The subsequent behavior is server dependent. In this example (IIS), the server will stop communication on unsuccessful authentication.
当服务端收到 AUTHENTICATE_MESSAGE 认证消息之后, 除了做常规的认证处理之外, 它还校验频道绑定数据, 与客户端同样计算一遍. 如果频道绑定数据不匹配, 认证就失败. 之后的行为就和服务器相关. 在这个例子中(IIS), 服务器会停止通信.
Please note that two step hashing is being employed here. First the application creates a hash of the certificate which becomes a part of gss_channel_bindings_struct structure. This structure is MD5 hashed again to be included in AUTHENTICATE_MESSAGE.
请注意, 这里应用了2步哈希. 首先应用程序计算证书的哈希值, 使其成为 gss_channel_bindings_struct结构的一部分. 这个结构又被计算MD5 哈希值, 用来包含在 AUTHENTICATE_MESSAGE中.
There are configurations on both Windows client and server side to disable the EPA. For the server side, please consult the server specific documentation. As for the server in this example, IIS, please consult http://www.iis.net/configreference/system.webserver/security/authentication/windowsauthentication/extendedprotection.
在Windows客户端和服务端都有配置来禁用EPA. 对于服务端, 请参考服务端规范. 对于本例中使用的IIS, 请参考:
http://www.iis.net/configreference/system.webserver/security/authentication/windowsauthentication/extendedprotection
On the client side, there is a registry setting that is described in KB976918 (http://support.microsoft.com/kb/976918) that can be used to configure EPA.
对于客户端, KB976918 描述了一个注册表设置(http://support.microsoft.com/kb/976918) 能用来配置EPA.
==============================
本文不是完全对照翻译,但是力求主题意思清楚。 请参考原文阅读:
NTLM and Channel Binding Hash (aka Extended Protection for Authentication) - Microsoft Open Spec
欢迎大家交流讨论。
-
Ubuntu 修改主机名/机器名
修改 /etc/hostname 和 /etc/hosts 文件对应的机器名
-
学一点 mysql 双机异地热备份----mysql主从,主主备份原理及实践
简单介绍mysql双机,多机异地热备简单原理实战。
双机热备的概念简单说一下,就是要保持两个数据库的状态自动同步。对任何一个数据库的操作都自动应用到另外一个数据库,始终保持两个数据库数据一致。 这样做的好处多。 1. 可以做灾备,其中一个坏了可以切换到另一个。 2. 可以做负载均衡,可以将请求分摊到其中任何一台上,提高网站吞吐量。 对于异地热备,尤其适合灾备。废话不多说了。我们直接进入主题。 我们会主要介绍两部分内容:
一, mysql 备份工作原理
二, 备份实战
我们开始。
我使用的是mysql 5.5.34,

一, mysql 备份工作原理
简单的说就是把 一个服务器上执行过的sql语句在别的服务器上也重复执行一遍, 这样只要两个数据库的初态是一样的,那么它们就能一直同步。
当然这种复制和重复都是mysql自动实现的,我们只需要配置即可。
我们进一步详细介绍原理的细节, 这有一张图:
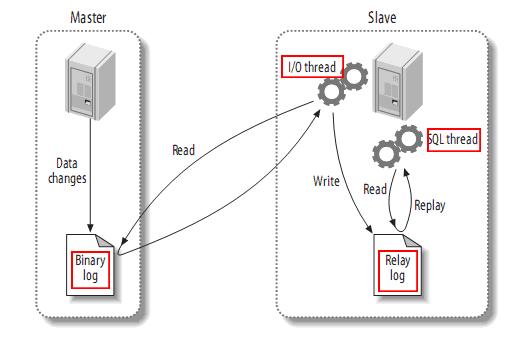
上图中有两个服务器, 演示了从一个主服务器(master) 把数据同步到从服务器(slave)的过程。
这是一个主-从复制的例子。 主-主互相复制只是把上面的例子反过来再做一遍。 所以我们以这个例子介绍原理。
对于一个mysql服务器, 一般有两个线程来负责复制和被复制。当开启复制之后。
1. 作为主服务器Master, 会把自己的每一次改动都记录到 二进制日志 Binarylog 中。 (从服务器会负责来读取这个log, 然后在自己那里再执行一遍。)
2. 作为从服务器Slave, 会用master上的账号登陆到 master上, 读取master的Binarylog, 写入到自己的中继日志 Relaylog, 然后自己的sql线程会负责读取这个中继日志,并执行一遍。 到这里主服务器上的更改就同步到从服务器上了。
在mysql上可以查看当前服务器的主,从状态。 其实就是当前服务器的 Binary(作为主服务器角色)状态和位置。 以及其RelayLog(作为从服务器)的复制进度。
例如我们在主服务器上查看主状态:

mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000014 Position: 107 Binlog_Do_DB: Binlog_Ignore_DB: mysql,information_schema,performance_schema,amh 1 row in set (0.00 sec)稍微解释一下这几行的意思:
1. 第一行表明 当前正在记录的 binarylog文件名是: mysql-bin.000014.
我们可以在mysql数据目录下,找到这个文件:

2. 第二行, 107. 表示当前的文件偏移量, 就是写入在mysql-bin.000014 文件的记录位置。
这两点就构成了 主服务器的状态。 配置从服务器的时候,需要用到这两个值。 告诉从服务器从哪读取主服务器的数据。 (从服务器会登录之后,找到这个日志文件,并从这个偏移量之后开始复制。)
3. 第三行,和第四行,表示需要记录的数据库和需要忽略的数据库。 只有需要记录的数据库,其变化才会被写入到mysql-bin.000014日志文件中。 后面会再次介绍这两个参数。
我们还可以在从服务器上,查看从服务器的复制状态。

mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 198.**.***.*** Master_User: r******* Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000014 Read_Master_Log_Pos: 107 Relay_Log_File: mysqld-relay-bin.000013 Relay_Log_Pos: 253 Relay_Master_Log_File: mysql-bin.000014 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: mysql,information_schema,amh,performance_schema Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 107 Relay_Log_Space: 556 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No我们还是来重点解释途中的红圈的部分:
1. Master_host 指的是 主服务器的地址。
2. Master_user 指的是主服务器上用来复制的用户。 从服务器会用此账号来登录主服务。进行复制。
3. Master_log_file 就是前面提到的, 主服务器上的日志文件名.
4. Read_Master_log_pos 就是前面提到的主服务器的日志记录位置, 从服务器根据这两个条件来选择复制的文件和位置。
5. Slave_IO_Running: 指的就是从服务器上负责读取主服务器的线程工作状态。 从服务器用这个专门的线程链接到主服务器上,并把日志拷贝回来。
6. Slave_SQL_Running: 指的就是专门执行sql的线程。 它负责把复制回来的Relaylog执行到自己的数据库中。 这两个参数必须都为Yes 才表明复制在正常工作。
其他的参数之后再介绍。
二, mysql 双机热备实战
了解了上面的原理之后, 我们来实战。 这里有两个重点, 要想同步数据库状态, 需要相同的初态,然后配置同步才有意义。 当然你可以不要初态,这是你的自由。 我们这里从头开始配置一遍。

我们先以A服务器为起点, 配置它的数据库同步到B。 这就是主-从复制了。 之后再反过来做一次,就可以互相备份了。
1, 第一步,
在A上面创建专门用于备份的 用户:

grant replication slave on *.* to 'repl_user'@'192.***.***.***' identified by 'hj34$%&mnkb';
上面把ip地址换成B机器的ip地址。 只允许B登录。安全。
用户名为: repl_user
密码为: hj34$********nkb
这个等会在B上面要用。
2. 开启主服务器的 binarylog。
很多服务器是默认开启的,我们这里检查一下:
打开 /etc/my.cnf

我来解释一下红框中的配置:
前面三行, 你可能已经有了。
binlog-do-db 用来表示,只把哪些数据库的改动记录到binary日志中。 可以写上关注hello数据库。 但是我把它注释掉了。 只是展示一下。 可以写多行,表示关注多个数据库。
binlog-ignore-db 表示,需要忽略哪些数据库。我这里忽略了其他的4个数据库。
后面两个用于在 双主(多主循环)互相备份。 因为每台数据库服务器都可能在同一个表中插入数据,如果表有一个自动增长的主键,那么就会在多服务器上出现主键冲突。 解决这个问题的办法就是让每个数据库的自增主键不连续。 上图说是, 我假设需要将来可能需要10台服务器做备份, 所以auto-increment-increment 设为10. 而 auto-increment-offset=1 表示这台服务器的序号。 从1开始, 不超过auto-increment-increment。
这样做之后, 我在这台服务器上插入的第一个id就是 1, 第二行的id就是 11了, 而不是2.
(同理,在第二台服务器上插入的第一个id就是2, 第二行就是12, 这个后面再介绍) 这样就不会出现主键冲突了。 后面我们会演示这个id的效果。
3. 获取主服务器状态, 和同步初态。
假设我现在有这些数据库在A上面。
如果你是全新安装的, 那么不需要同步初态,直接跳过这一步,到后面直接查看主服务器状态。
这里我们假设有一个 hello 数据库作为初态。

先锁定 hello数据库:
FLUSH TABLES WITH READ LOCK;

然后导出数据:
我这里只需要导出hello数据库, 如果你有多个数据库作为初态的话, 需要导出所有这些数据库:

然后查看A服务器的binary日志位置:
记住这个文件名和 位置, 等会在从服务器上会用到。

主服务器已经做完了, 可以解除锁定了:

4. 设置从服务器 B 需要复制的数据库
打开从服务器 B 的 /etc/my.cnf 文件:

解释一下上面的内容。
server-id 必须保证每个服务器不一样。 这可能和循环同步有关。 防止进入死循环。
replicate-do-db 可以指定需要复制的数据库, 我这里注掉了。 演示一下。
replicate-ignore-db 复制时需要排除的数据库, 我使用了,这个。 除开系统的几个数据库之外,所有的数据库都复制。
relay_log 中继日志的名字。 前面说到了, 复制线程需要先把远程的变化拷贝到这个中继日志中, 在执行。
log-slave-updates 意思是,中继日志执行之后,这些变化是否需要计入自己的binarylog。 当你的B服务器需要作为另外一个服务器的主服务器的时候需要打开。 就是双主互相备份,或者多主循环备份。 我们这里需要, 所以打开。
保存, 重启mysql。
5. 导入初态, 开始同步。
把刚才从A服务器上导出的 hello.sql 导入到 B的hello数据库中, 如果B现在没有hello数据库,请先创建一个, 然后再导入:
创建数据库:
create database hello default charset utf8;
把hello.sql 上传到B上, 然后导入:

如果你刚才导出了多个数据库, 需要把他们都一一上传导入。
开启同步, 在B服务器上执行:
CHANGE MASTER TO MASTER_HOST='192.***.***.***', MASTER_USER='repl_user', MASTER_PASSWORD='hj3****', MASTER_LOG_FILE='mysql-bin.000004', MASTER_LOG_POS=7145;
上面几个参数我就不解释了。 前面说过了。
重启mysql, 然后查看slave线程开启了没:

注意图中的红框, 两个都是Yes, 说明开启成功。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
如果其中一个是No, 那就说明不成功。需要查看mysql的错误日志。 我在第一次做的时候就遇到这个问题。有时候密码填错了, 有时候防火墙的3306没有打开。ip地址不对,等等。 都会导致失败。
我们看错误日志: mysql的错误日志一般在:

文件名应该是你的机器名, 我这里叫做host1.err 你换成你自己的。
到这里主-从复制已经打开了。 我们先来实验一下。
我们在A的数据库里面去 添加数据:

我在A的 hello数据库的test表中 连续插入了3条数据, 注意看他们的自增长id, 分别是1,11,21. 知道这是为什么吗。 前面已经说过了,不懂再回去看。
我们去看一下B数据库有没有这三条数据:
打开B的数据库:

发现已经在这了。 这里效果不直观。
此时不要在B中修改数据。 我们接着配置从B到A的复制。 如果你只需要主从复制的话, 到这里就结束了。后面可以不看了。 所有A中的修改都能自动同步到B, 但是对B的修改却不能同步到A。 因为是单向的。 如果需要双向同步的话,需要再做一次从B到A的复制。
基本跟上面一样:我们简单一点介绍:
1. 在B中创建用户;

2. 打开 /etc/my.cnf , 开启B的binarylog:

注意红框中所新添加的部分。
3. 我们不需要导出B的初态了,因为它刚刚才从A导过来。 直接记住它的master日志状态:

记住这两个数值,等会在A上面要用。
B服务器就设置完了。
4. 登录到A 服务器。 开启中继:

注意框中心添加的部分, 不解释了。
5. 启动同步:

上面的ip地址是B的ip地址, 因为A把B当做master了。 不解释了。
然后重启mysql服务。
然后查看,slave状态是否正常:

图中出现了两个No。
Slave_IO_Running: No
Slave_SQL_Running: No
说明slave没有成功, 即,从B到A的同步没有成功。 我们去查看mysql错误日志,前面说过位置:

找到 机器名.err 文件,打开看看:

看图中的error信息。 说找不到中继日志文件。
这是因为我们在配置A的中继文件时改了中继文件名,但是mysql没有同步。解决办法很简单。

先停掉mysql服务。 找到这三个文件,把他们删掉。 一定要先停掉mysql服务。不然还是不成功。你需要重启一下机器了。 或者手动kill mysqld。
好了, 启动mysql之后。 我们在来检查一下slave状态:

注意图中两个大大的Yes。 哈哈。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
证明从B到A的复制也成功了。
此时我们去B服务器中插入几条数据试试:

我在B中插入了两条数据。 注意看他们的id。 不解释。
然后我们,登录去A中看看,A数据库变了没。

可以看到已经自动同步到A了。
至此, AB双主互相热备就介绍完了。
原理其实很简单,是不是。
理解了这个原理, 多机循环互备就简单了。这里就不再展开了。
花了一天时间写这个博客,大家要顶啊。
欢迎大家访问我的独立博客:http://blog.byneil.com 多多交流。
参考:
1. mysql-keepalived-实现双主热备读写分离
2. MySQL数据同步【双主热备】http://www.cnblogs.com/zhongweiv/archive/2013/02/01/mysql_replication_circular.html
3. Mysql双机热备实现
http://yunnick.iteye.com/blog/1845301
4. 高性能Mysql主从架构的复制原理及配置详解http://blog.csdn.net/hguisu/article/details/7325124
-
简单配置vps,防ddos攻击
防人之心不可无。 网上总有些无聊或者有意的人。不多说了。上干货,配置vps apf防小流量ddos攻击。
对于大流量的ddos攻击, 需要机房的硬件防火墙,vps内部可能也扛不住。
1. 安装 DDoS deflate
DDoS deflate的原理是通过netstat命令找出 发出过量连接的单个IP,并使用iptables防火墙将这些IP进行拒绝。由于iptables防火墙拒绝IP的连接远比从Apache层面上来得高效,因此iptables便成了运行在Apache前端的“过滤器”。同样的,DDoS deflate也可以设置采用APF(高级防火墙)进行IP阻止。
wget http://www.inetbase.com/scripts/ddos/install.sh chmod +x install.sh ./install.sh
主要功能与配置
1、可以设置IP白名单,在 /usr/local/ddos/ignore.ip.list 中设置即可;
2、主要配置文件位于 /usr/local/ddos/ddos.conf ,打开此文件,根据提示进行简单的编辑即可;
3、DDoS deflate可以在阻止某一IP后,隔一段预置的时候自动对其解封;
4、可以在配置文件中设置多长时间检查一次网络连接情况;
5、当阻止IP后,可以设置Email提醒
简单配置一下:
FREQ=1 #检测的频率为1分钟 NO_OF_CONNECTIONS=100 #当单个IP超过100个连接请求时判定为DDOS APF_BAN=1 #如果打算使用APF阻止IP,则设置为1(需要预先安装APF);如果使用iptables,则设置为0; KILL=1 #是否阻止 EMAIL_TO="webmaster@firstVM.com" #接收邮件 BAN_PERIOD=600 #阻止时长,10分钟
2. 安装配置apf。
APF(Advanced Policy Firewall)是 Rf-x Networks 出品的Linux环境下的软件防火墙,被大部分Linux服务器管理员所采用,使用iptables的规则,易于理解及使用。
适合对iptables不是很熟悉的人使用,因为它的安装配置比较简单,但是功能还是非常强大的。
脚本安装:
root@linux:/home/zhangy# wget http://www.rfxnetworks.com/downloads/apf-current.tar.gz root@linux:/home/zhangy# tar -xvzf apf-current.tar.gz root@linux:/home/zhangy# cd apf-9.7-1 root@linux:/home/zhangy/apf-9.7-1# ./install.sh
ubuntu 可以快速安装:
sudo aptitude install apf-firewall
配置:
vi /etc/apf/conf.apf
往后翻页,找到:
# Configure inbound (ingress) accepted services. This is an optional # feature; services and customized entries may be made directly to an ip's # virtual net file located in the vnet/ directory. Format is comma separated # and underscore separator for ranges. # # Example: # IG_TCP_CPORTS="21,22,25,53,80,443,110,143,6000_7000" # IG_UDP_CPORTS="20,21,53,123" # IG_ICMP_TYPES="3,5,11,0,30,8" # Common inbound (ingress) TCP ports IG_TCP_CPORTS="22"
默认只有22端口开放。 我们先不管。 访问以下80端口的网站试试。 发现竟然可以访问。 为什么规则没有起作用。
继续查看配置文件。 找啊找。
这一行引起了我的注意:
# Untrusted Network interface(s); all traffic on defined interface will be # subject to all firewall rules. This should be your internet exposed # interfaces. Only one interface is accepted for each value. IFACE_IN="eth0"
突然想到, 会不会是监听端口的问题。
我们知道, 如果是真实服务器或者是 xen虚拟化的vps, 其网卡是 eth*。 例如:
ifconfig

但是, 我这台vps是openvz虚拟化的。 它的网卡一般是 vnet* 的。 比如:

于是改上面的配置文件:
# Untrusted Network interface(s); all traffic on defined interface will be # subject to all firewall rules. This should be your internet exposed # interfaces. Only one interface is accepted for each value. IFACE_IN="venet0"
重启 apf:
apf -r
提示说找不到 ip_tables 模块。
ip_tables
apf(4677): {glob} unable to load iptables module (ip_tables), aborting.

于是搜索: ubuntu apf 找到这篇文章
http://davidwinter.me/articles/2011/06/05/install-apf-on-ubuntu-11-04/
大致意思是说, 在ubuntu中, iptables默认被编译进了内核, 而不是以模块方式运行的。apf默认是使用模块方式调用iptables。 所以要修改apf的配置:
SET_MONOKERN="1"
然后重启 apf
然后看到一长串的日志:

看样子是成功了。
试一下, 果然80端口不能访问了。
只有22还在。
回到配置文件, 我们把端口开放:
vi /etc/apf/conf.apf
找到:
# Configure inbound (ingress) accepted services. This is an optional # feature; services and customized entries may be made directly to an ip's # virtual net file located in the vnet/ directory. Format is comma separated # and underscore separator for ranges. # # Example: # IG_TCP_CPORTS="21,22,25,53,80,443,110,143,6000_7000" # IG_UDP_CPORTS="20,21,53,123" # IG_ICMP_TYPES="3,5,11,0,30,8" # Common inbound (ingress) TCP ports IG_TCP_CPORTS="22,80,443"
保存,重启: apf –r
再访问以下,成功了。
最后, 关闭apf的调试模式,正式上线:
找到:
# !!! Do not leave set to (1) !!! # When set to enabled; 5 minute cronjob is set to stop the firewall. Set # this off (0) when firewall is determined to be operating as desired. DEVEL_MODE="1"
改成 0:
# !!! Do not leave set to (1) !!! # When set to enabled; 5 minute cronjob is set to stop the firewall. Set # this off (0) when firewall is determined to be operating as desired. DEVEL_MODE="0"
加入到自动启动:
找到这个文件:
/etc/default/apf-firewall
找到:
RUN="no" 改为RUN="yes"欢迎大家访问我的个人独立博客: http://blog.byneil.com
-
Ubuntu 下完全卸载 apache2
Ubuntu自带 apache2 有时候很讨厌。 有时候需要先卸载了再装别的。
这里找了一个完全卸载的方法:
sudo apt-get autoremove apache2 -y sudo apt-get remove apache* -y sudo apt-get --purge remove apache-common -y sudo apt-get --purge remove apache -y sudo find /etc -name "*apache*" |xargs rm -rf sudo rm -rf /var/www sudo rm -rf /etc/libapache2-mod-jk dpkg -l |grep apache2|awk '{print $2}'|xargs dpkg -Phave fun.
































