Welcome to Neilpang's Blog!
记录生活,分享知识,传播乐趣-
7z文件格式及其源码的分析(五)
这是7z文件格式及其源码的分析系列的第五篇. 上一篇讲到了7z文件压缩流程。最近太忙了,好久没更新,都快忘了写到哪了。:)
这一篇就说说7z文件的尾头的生成方式吧。 上一篇已经讲了尾header的结构了。它其实就是记录了压缩文件详细信息。
那么尾header是如何存储的呢?
先看一个图:

这是整个7z文件的结构。 最后面的绿色“尾文件头” 就是我们要说的目标。
7z的尾文件头有两种存储方式。
第一, 最简单的, 就是把尾文件头的内容直接写在后面, 不做任何处理。
这种方式最简单,但是却最不常用。 原因是什么。 我们看上一篇中说到的尾文件头的内容就知道了。 举个简单的例子, 比方说你要压缩大量的文件,比如100个文件吧。 为文件头里面就会有大量的空间用来存储文件名,文件大小,文件时间等等。 通常这些信息很多,但是有个共同特点就是重复信息多。 我们知道,对于这些简单的文本信息,其可压缩性非常强。 换句话说,这些信息的压缩比特别大。 于是, 这就引出了,另一种压缩方式。
第二, 把原始的尾header信息用lzma算法再压缩一次。这样可以显著的减少尾header的大小。尤其是在大量文件的时候。
我们来看一个图:

实际怎么生成的呢。 这其实是一个递归过程。
尾文件头压缩的思路就是把原始的尾文件头数据当做一个单独的文件流来进行一次前面的压缩过程。就是重复一次前面的7z的压缩过程。 不过这一次只有一个文件,因此只划分一个Folder. 而且压缩方法是指定的LZMA。也就是说只有一个Coder参与。 当然,原始尾文件头的内容可能有敏感信息。 比如里面的文件名等等信息。因此,7z也提供能力在压缩尾文件头的时候同时加密它。 所以压缩尾文件头的时候如果选择加密头信息,则会加入AES Coder加密。
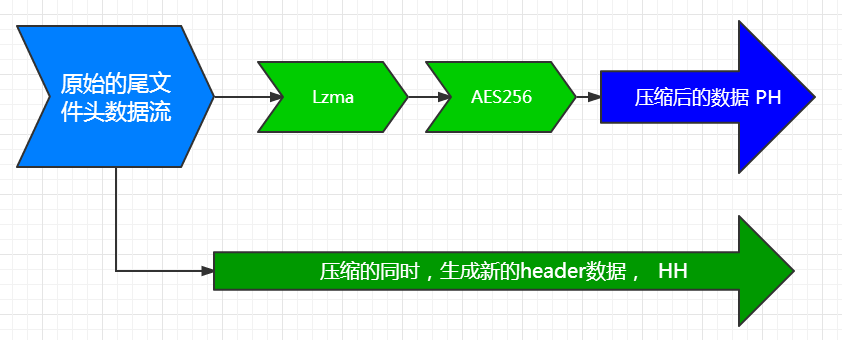
所以实际尾header就是这样存储的,上面的 PH, 和HH。
用户在压缩7z文件的时候,可以选择是否加密文件, 并且可以同时选择是否加密文件头。
如果用户只加密文件,而不加密文件头。 这样的文件,双击直接用7z打开,可以看到里面的文件结构。文件详细信息,但是不能解压文件出来,除非有密码。
如果同时选择加密文件和文件头。 双击这样的文件,7z会直接提示请输入密码,否则连文件结构都看不见。 原因就在这里。 因为文件的结构信息也被加密了,没有密码,连文件头都解压不开。
这一点必zip文件先进, zip只支持文件内容加密。
暂时就到这吧。欢迎大家访问我的个人独立博客:http://byNeil.com
下一篇给大家介绍7z如何实现流式压缩和解压的, 以及其他一些7z的trick。
-
zip 压缩文件名的unicode(utf-8)支持
参见:http://www.pkware.com/documents/casestudies/APPNOTE.TXT
Bit 11: Language encoding flag (EFS). If this bit is set, the filename and comment fields for this file MUST be encoded using UTF-8. (see APPENDIX D)D.1 The ZIP format has historically supported only the original IBM PC character encoding set, commonly referred to as IBM Code Page 437. This limits storing file name characters to only those within the original MS-DOS range of values and does not properly support file names in other character encodings, or languages. To address this limitation, this specification will support the following change.
zip 文件头标志位的第11个位表示是否支持unicode文件名.
如果为0, 表示默认的使用 IBM 437 编码,
如果为1, 表示使用unicode文件名, 并且 文件名一定使用的是utf-8编码.
概括起来, zip格式本来只支持英文 IBM437编码. 后来扩展了这个标记. 表示文件名是用utf-8编码表示的.
并且zip只支持utf-8.
-
Tcp 断开连接,及linger
tcp 的断开过程:
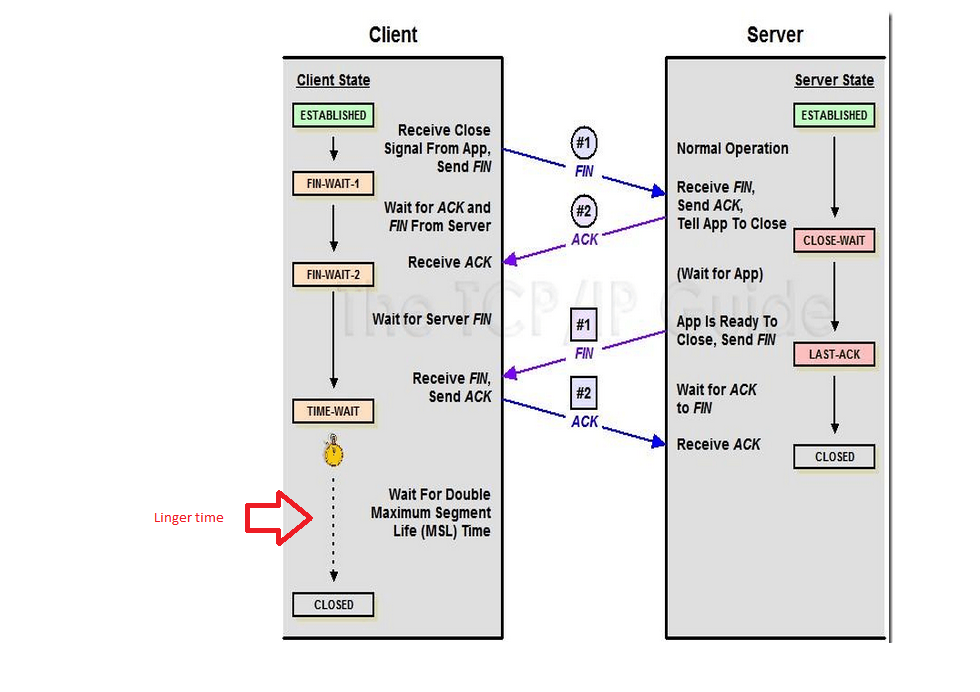
只有 client (主动发起断开的一方) 在进入 time_wait 之后会等待一个时间, 这个时间就是linger time.
1. 如果设置linger 为 0, 则主动断开的一方 直接发送RST给对方,然后自己立即结束. 不会进行4次挥手过程.
2. 默认情况下,linger为1, 主动断开的一方会发送FIN给对方, 然后等待进行完整的 4次挥手. 然后, 主动一方会进入一个linger状态, 持续时间为lingertime, 如果设置lingertime为0, 则使用系统的默认时间, 这个时间一般是 2MSL. 如果指定了 LingerTime, 则使用lingertime. 处于linger状态的socket, 查看状态是 time_wait. 不会进行任何操作. 等lingertime时间到了, 就会自动消失了.
-
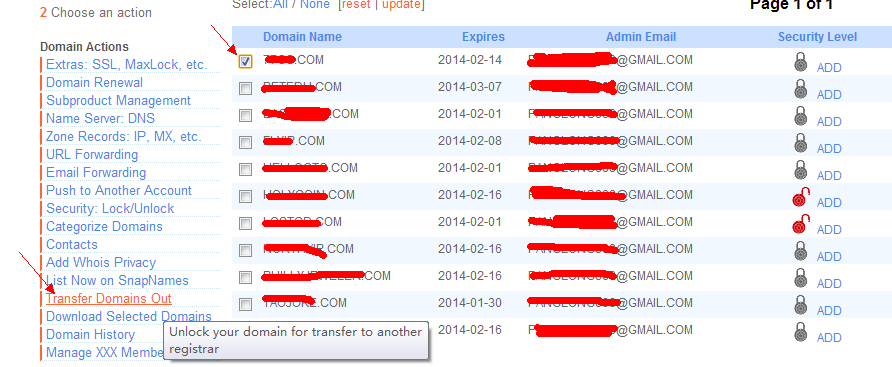
如何从snapnames获得域名转移码
在snapnames购买的域名会被系统自动加上转移保护, 官方说只要你选择transfer out域名之后, 转移锁会自动解除, 同时系统把转移码发送到你的邮箱里面:
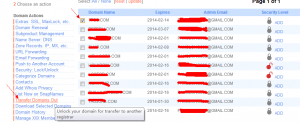
然后再保存一下:
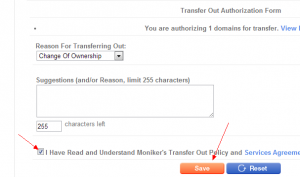
正常情况下, 域名锁已经解除, 并且你的邮箱应该收到转移码了。
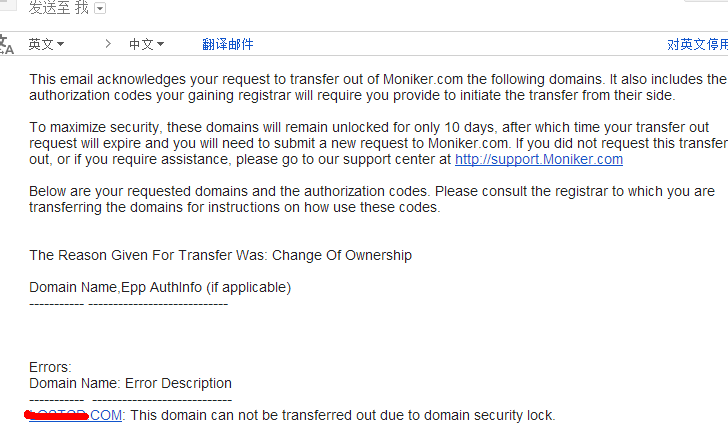
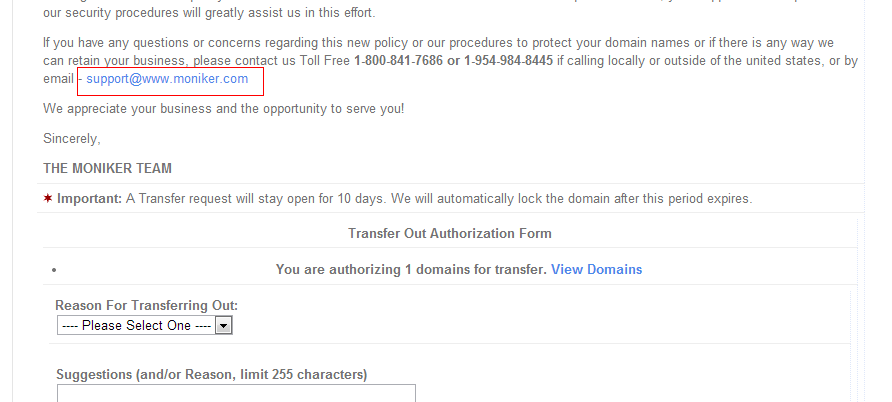
但是我这次转移却失败了。收到邮件:
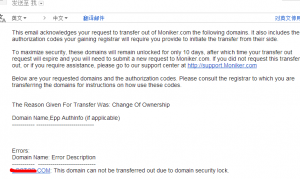
This email acknowledges your request to transfer out of Moniker.com the following domains. It also includes the authorization codes your gaining registrar will require you provide to initiate the transfer from their side.
To maximize security, these domains will remain unlocked for only 10 days, after which time your transfer out request will expire and you will need to submit a new request to Moniker.com. If you did not request this transfer out, or if you require assistance, please go to our support center at http://support.Moniker.com
Below are your requested domains and the authorization codes. Please consult the registrar to which you are transferring the domains for instructions on how use these codes.
The Reason Given For Transfer Was: Change Of Ownership
Domain Name,Epp AuthInfo (if applicable)
----------- ----------------------------Errors:
Domain Name: Error Description
----------- ----------------------------
XXXXXXXXXX: This domain can not be transferred out due to domain security lock.说因为安全原因。
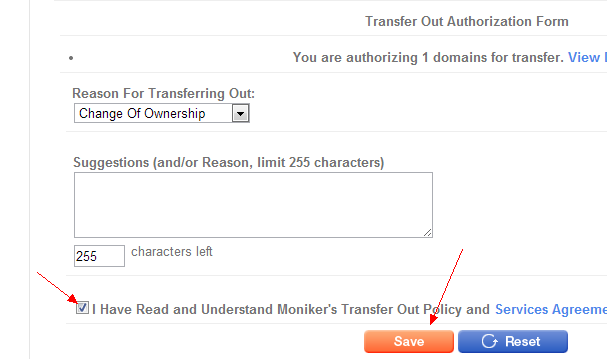
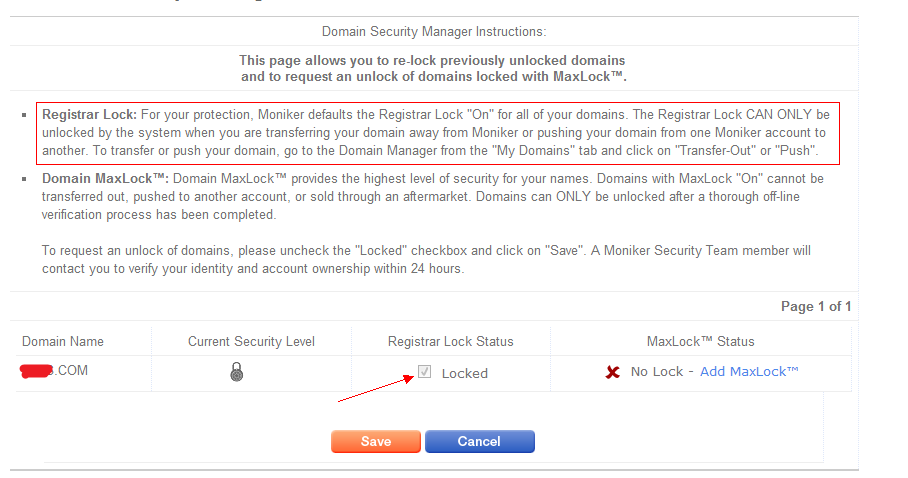
于是尝试手动去除安全锁:
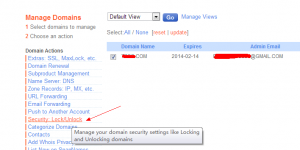
然后:
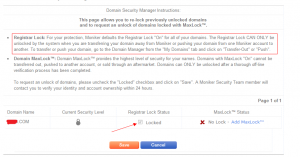
框是灰色的,不能选。 上面也说明了, 安全锁只能在转出时自动解除,不能手动解除。
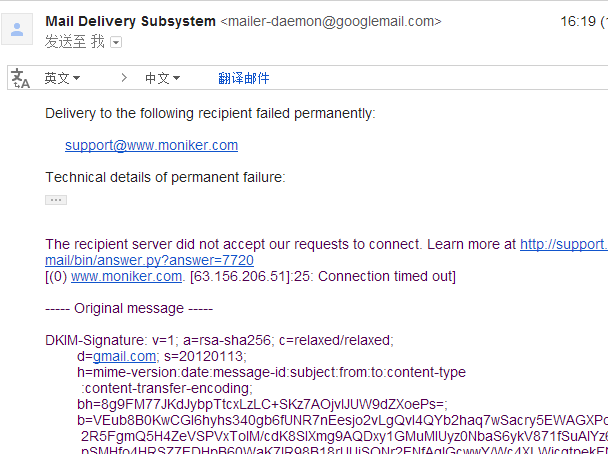
试了很多次,都不行, 于是找到页面上的客服邮箱写信:
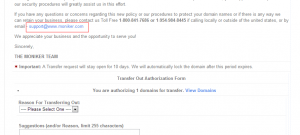
没想到,第二天,收到退信, 这个邮箱竟然不存在。
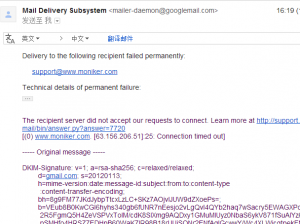
没想到, 这么坑爹。
怎么办。 这难住了我几天。
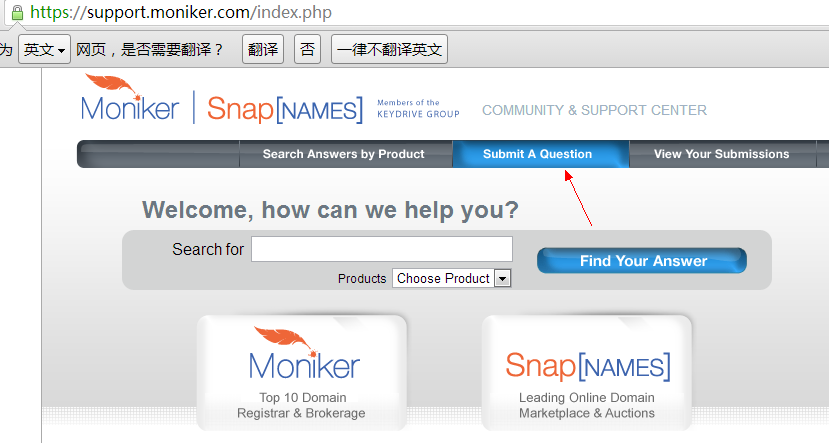
最后抱着试一试的态度, 点开support网站, 找到提交问题的地方:
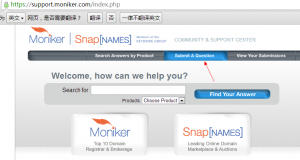
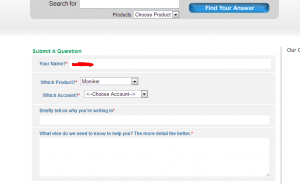
填写了要求转出的信息。
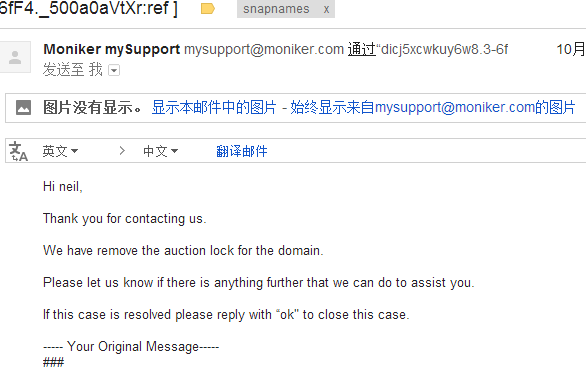
等了一天, 这次终于收到了回复:
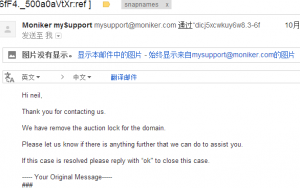
说已经解除了拍卖锁, 然后我再次transfer out, 果然成功了。
再去转别的域名, 还是转不成功。 于是我再次写信去,语气比较严重, 要他们把我所有的域名都解锁。
好吧, 大家记得以后有问题去support网站提交问题吧,不要直接发邮件了。
-
Windows 8.1 设置本地账户的方法
刚安装windows 8.1正式版, 安装完成之后, 提示设置账户. 貌似只能设置微软的在线账户, 之前的windows8有个选项可以只设置本地账户. 对于这种"改进", 我只想对微软说两个字: 呵呵.
幸好在网上找到了两个方法可以绕过:
1. 拔掉网线, 后退到上一步, 然后在下一步. 系统检测到你没有联网, 就不会提示设置在线账户了. 直接提示设置本地账户.
2. 如果你不喜欢这么暴力的方法, 还有比较文艺一点的. 在设置在线账户的框里面, 随便输入一个邮箱, 和一个密码, 系统检测不到账户, 就会在后面出现一行小字, 点击就可以创建本地账户了.
Have fun.
-
7z文件格式及其源码的分析(四)
这是7z文件格式及其源码的分析系列的第四篇. 上一篇讲到了7z文件静态结构的尾header部分.这一篇开始,将从7z实际压缩流程开始详细介绍7z文件尾header的详细结构.
一, 第一个概念: coder.
在7z的压缩过程中, 一个非常核心的概念就是coder. 一个coder代表一个算法, 通常是指一个压缩或解压算法(也包括过滤算法和加密算法等). 例如, 在7z中lzma算法就是一个coder, deflate算法也是一个coder. 7z中用于加密的AES256算法也是一个coder.
所以概念上讲, 能处理一个文件流的算法就是一个coder. 这个"处理"的概念可以是压缩/解压, 加密等等.
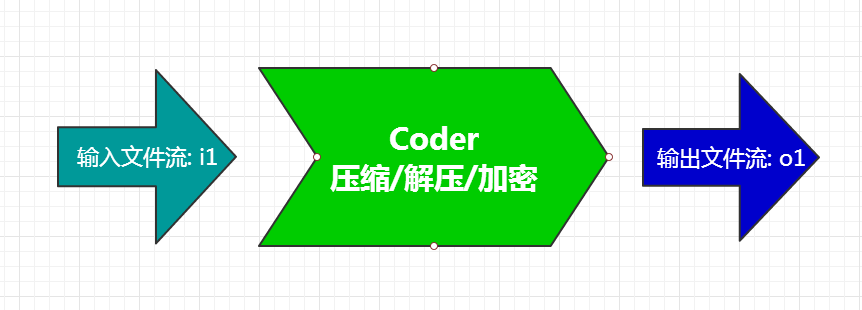
(图1)
通常来讲, 一个coder只能处理一个输入流, 并且只有一个输出流. 比如把一个文件流压缩成一个输出流. 但是, 7z中有的coder可以把一个输入流处理成多个输出流, 反过来也可以把多个流处理成一个流. 比如7z的 BCJ2 coder, 它是一个过滤coder, 可以把一个exe文件过滤成四个输出流. 这样的话, 7z的coder概念得到了扩展. 就是可能同时处理多个输入流, 并且可能输出多个流:
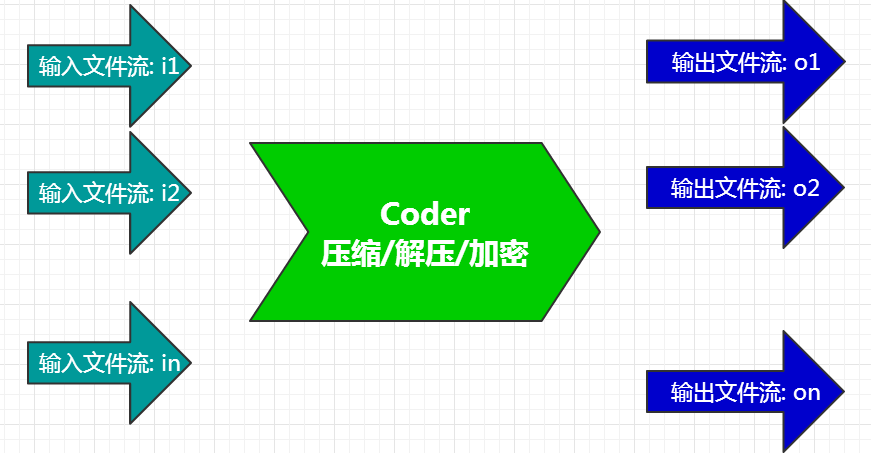
(图2)
这里可以先简单的体验一下压缩的过程了:
1. 简单压缩过程, 把文件流交给lzma coder压缩.
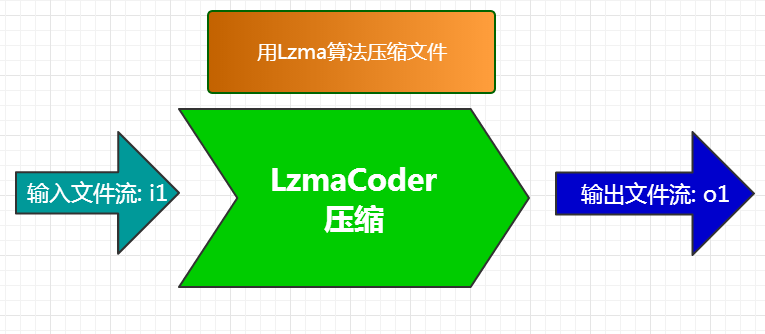
(图3)
2. 多coder串联, 理论上可以串联任何两个coder, 而且串联的级数也是没有限制的, 可以串联任意多级. 当然, 由于熵的存在, 串联过个压缩coder是没有意义的.
这里示例的是最常用的一种方式,就是压缩并且加密.
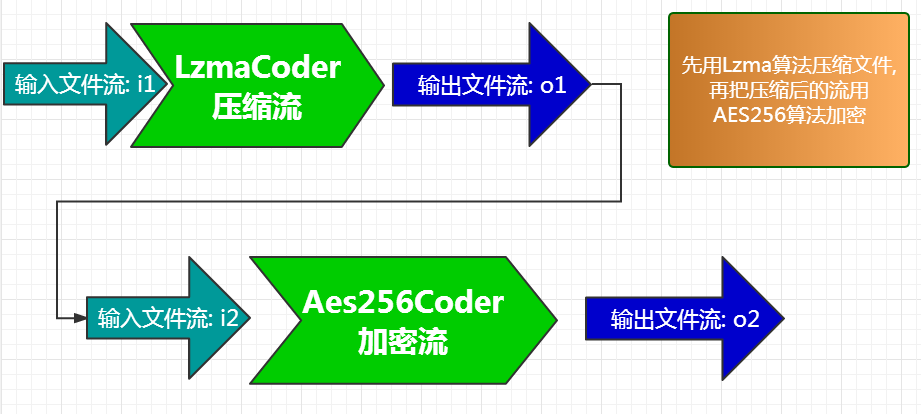
(图4)
注意上图中的o1, 和 i2. o1是第一个coder的输出流, i2是第二个coder的输入流. 在实际操作中, 这两个流其实是同一个流, 直接把第一个的输出当做第二个的输入.
解压的过程就是上面的逆过程.
上图就是比较完整的一次压缩过程了.
二, 第二个概念 Folder, 不是文件夹.
这里的Folder要特别注意, 它不是我们通常指的文件夹. 它也不是任何物理上存在的东西.
7z在开始压缩之前, 会把文件分类, 大体上是按文件类型以及文件是否需要加密来分类的. 比如说, 把所有的exe文件分成一类(一个Folder), 或者把所有需要加密的文件分在一起. 等等. 具体分类方法以后再说. 这个分类方法并不重要, 7z的实现用的方法比较简单. 实际上如果要实现7z的压缩器的话, 这个分类方法你说了算. 你可以给每个文件划分成一个Folder.
我们看一个例子:
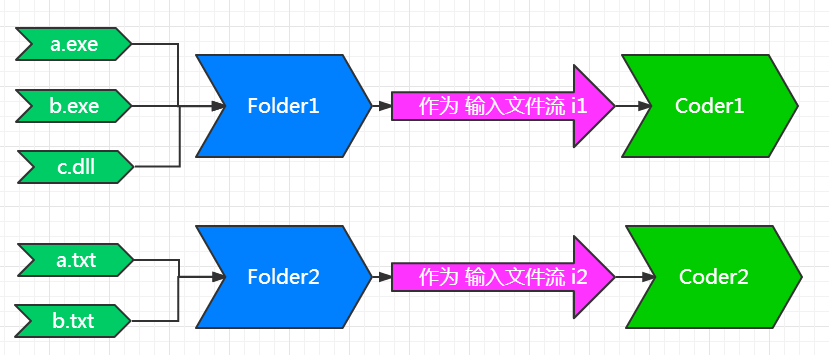
(图5)
在这个例子中, 我们共有5个文件需要压缩.
1. 首先, 通过一定的分组方法, 我们分成了两个Folder, 第一个Folder包括: a.exe, b.exe 和 c.dll 三个文件. 第二个Folder包括:a.txt 和 b.txt.
2. 对Folder1来说, 它包含三个文件, Folder1就简单的把三个文件串联起来,当做一个大文件, 作为输入流 i1 给Coder1 用. 后面的过程就就是上面的 图4 的内容了.
在7z源码的: \CPP\7zip\Archive\7z\ 这个目录下,有 7zFolderInStream.h 和7zFolderInStream.cpp 专门处理把多个文件串联伪装成一个文件的任务. 从Coder1 的角度看, 它只知道有个文件流 i1, 并不知道这个i1 是一个真实的文件 还是由一个Folder伪装的.
实际上, 7z概念上最小的压缩单位不是文件, 而是Folder, 它会先把所有的文件都归到一个相应的Folder中, 然后 让这个Folder作为文件流, 流过若干个Coder. 我们再抽象一下上面的压缩过程:
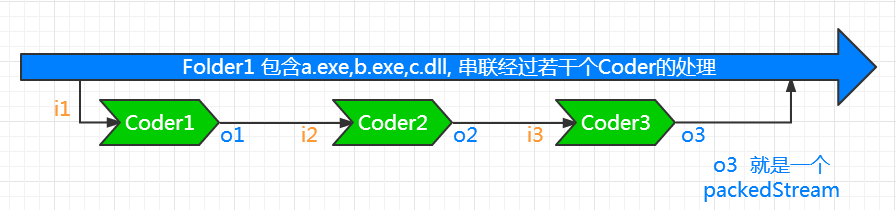
(图 6)
上图中的字母 'i' 表示输入的意思, 'o' 表示输出. 后面的数字表示序号. 简单解释一下, 这个Folder流最初是作为Coder1 的输入流i1. Coder1 的输出流是o1. 这个o1又作为 i2 输入给Coder2用, 然后又是Coder3.
值得注意的是最后一个coder的输出流 o3. 它就是压缩的最终输出结果了. 它在7z中叫做一个PackedStream. 就是打包的流. 我们叫做p1吧. 如果有多个Folder, 那每个Folder就会有一个或多个PackedStream. 所以所有文件压缩之后就会有 pn. 这n个packedStream会被按顺序存储在 7z的文件主体, 就是上一篇文章中介绍的第二部分.
每个Folder 包含了哪些文件, 每个文件大小等等这些详细信息都存贮在7z的尾文件头中了. 在7zformat.txt中有这一段:
NumFolders Folders[NumFolders] { NumCoders CodersInfo[NumCoders] { ID NumInStreams; //表示这个coder 所接受的输入流的个数, 一般是1个 NumOutStreams; //表示这个coder的输出流的个数, 一般是1个. PropertiesSize //一个int值, 表示后面Properties的字节长度 Properties[PropertiesSize] // 字节数组, 表示这个coder的一些设置信息, 比如压缩级别, 或者AES加密的IV等等. } NumBindPairs // 表示bindpair 的个数. bindpair表示输入流和输出流的绑定关系. 例如上面的图6中, o1和i2是绑定的, o2和i3是绑定的. BindPairsInfo[NumBindPairs] //bindpair的数组, 记录每一个bindpair. { InIndex; //这个绑定的输入index, 就是上图中对应的 i后面的序号. (不好意思, 画图的时候没注意,图上下表是从1开始的,但是实际上,你懂的, 都是从0开始的.所有上面图中的下标都要减一.) OutIndex; //绑定对应的输出index, 就是对应上图中o后面的序号. 同上. } PackedIndices //这表示这个folder最终输出的packstream在所有packstream中的序号. } UnPackSize[Folders][Folders.NumOutstreams] // 这是一个二位数组, 记录每个Folder对应的输出流的个数. CRCs[NumFolders] //这是一个Crc的数组, 没个folder 流的crc, 7z目前没有使用这一个字段.稍微解释一下上面的结构:
1. NumFolders, 显示一个int32值, 它记录了7z文件中共有多少个Folder.
2. 后面那是folder数组, 一次排布每个Folder. 每个Folder结构如下:
3. NumCoders, int32值, 记录了这个Folder总共进过了几个coder.
4. 后面就是它的所有Coder的数组, 每个coder的结构: 显示一个coder 的id. 就是coder的唯一标示符. 这个id的定义在: DOC/目录下的 methods.txt.
5. 更详细的信息, 请看上面代码后面的注释吧.
6. 我再强调一点,我画图的时候没有注意,所以图中的i和o后面的序号都是从1开始的, 实际上,你懂的, 每个存储的序号都是从0开始的, 没有例外. 如果你发现哪里的序号和我说的不一样, 请检查这个. 没有例外, 所有的序号都是从0开始的. 包括以后我可能会画的图. 记住都是从0开始的.
7, 再有一点就是, 比如上图中的folder经过了 coder1, coder2 和coder3 这三个coder. 实际才存储这三个coder的时候, 是按逆序存储的, 就是先存Coder3, 然后是coder2, 最后是coder1. 这是为了方便解压.
上面的图6就是一次比较完整的压缩流程, 解压的流程就是反过来, 先分别构建coder1, coder2 和coder3, 然后逆向流动就最终解压了.
每个Folder都会经过一次完整的压缩过程.
好了, 主要的压缩过程和结构已经介绍完了. 下一篇将给大家介绍剩下的文件详细信息的存储方式, 以及最终的Header的生成方式.
最后还是欢迎大家访问我的独立博客: http://byNeil.com
写这么多字, 画图都不容易, 帮顶一下吧, 小伙伴们.