Welcome to Neilpang's Blog!
记录生活,分享知识,传播乐趣-
7z文件格式及其源码的分析(三)
上一篇在这里. 这是7z文件格式分析的第三篇, 相信有了前两篇的准备,你已经了解了7z源码的大致结构, 以及如何简单调试7z的源码了. 很多同学是不是迫不及待想要拔去7z的神秘外衣,看看究竟了. 好, 这就带你们一探乾坤. 本文开始,我们详细介绍7z的文件存储结构.
要了解7z的结构, 当然最好从官方的说明开始, 尽管这个说明非常简略, 但它的确是我入门时的救命稻草.
打开源码的 "DOC" 目录. 这里面就是官方所有的文档了. 其中只有二个文档跟结构相关:
1. 7zFormat.txt, 这是我们的主角, 里面介绍了7z文件的大体结构.
2. Methods.txt, 这里面介绍了7z压缩算法id的编码规则, 以后会用到.
我们从7zFormat.txt文件开始.
Archive structure ~~~~~~~~~~~~~~~~~ SignatureHeader [PackedStreams] [PackedStreamsForHeaders] [ Header or { Packed Header HeaderInfo } ]上面就是7z文件的总体结构了. 我来稍微解释一下. 上面的代码中, 从波浪线往后开始算. 7z的文件结构基本上分为三部分:
1. 前文件头(就是最前面的header).
2. 压缩数据.
3. 尾文件头(就是放在文件末尾的header).
一, 前文件头就是上图中的 "SignatureHeader". 它是32个字节定长的. 前文件头其实记录的信息很少, 它的主要目的是记录尾文件头的位置, 压缩的主要结构都是存在尾文件头中.
它的结构如下:
SignatureHeader ~~~~~~~~~~~~~~~ BYTE kSignature[6] = {'7', 'z', 0xBC, 0xAF, 0x27, 0x1C}; ArchiveVersion { BYTE Major; // now = 0 BYTE Minor; // now = 2 }; UINT32 StartHeaderCRC; StartHeader { REAL_UINT64 NextHeaderOffset REAL_UINT64 NextHeaderSize UINT32 NextHeaderCRC }先是固定的6个字节的值, 前两个字节的值是字母 '7' 和'z' 的ascii值. 后面四个字节是固定的: 0xbc, 0xaf, 0x27, 0x1c
然后是两个字节的版本号, 注意主版本号在前面, 次版本号在后面. 目前的版本号是: 0.2, 注意这是7z文件格式的版本号, 不是7z软件的版本号.
然后是四个字节的 UINT32 的值, (注意, 7z的所有数据都是采用小端在前的存储, 所以要注意这四个字节的实际存储顺序是低位字节在前面, 高位字节在后. 后面的所有数据都是这种结构, 所以以后就不再强调了. ) . 这4个字节的值是做什么的呢? 先抛开这四个字节本身, 前文件头的32个字节中, 已经用去了 6 + 2 +4 =12 个, 还剩下20个字节. 对了, 这四个字节就是剩下的20个字节的CRC校验值. 具体的CRC算法源码, 在源码中的 "C" 文件夹下的 '7zCrc.c' 和 '7zCrc.h'.
最后这20个字节要一起介绍了. 先是8个字节的UINT64的值, 它记录的是尾文件头(上图中的NextHeader)与前文件头的距离, 这个距离是不算前面这32个字节头的, 也就是抛开前面32个字节开始计数的(解压器通过读取这个值,然后从第33个字节开始直接跳过这个距离, 就可以找到尾文件头了). 然后是8个字节的值, 记录了尾文件头的大小(解压的时候, 通过这个值就能读出尾文件头的长度了). 最后还有4个字节的值, 它也是一个Crc校验值, 是整个尾文件头的校验值.
这里需要注意的是, 上图中用的是 "REAL_UINT64" 这个表达方式, 它的意思就是我们通常理解的占8个字节的UInT64的值(当然是小端存储的啦). 这里用了"real", 真. 那是不是还有"假"的InT64呢. 答案是肯定的. 7z为了兼容压缩大文件(大于4G),这个问题曾一度是zip文件的噩梦, 早期的zip只能压缩小于4G的文件, 并且压缩后的总文件大小也不能超过4G, 后来专门做了标准升级. 好了扯远了. 7z一早设计就考虑到了大文件的问题, 所以很多地方都必须用int64来表达, 这样也会带来一个问题, 就是绝大多数case下, 都不可能超过4G(试问一下,你平时有多少压缩文件超过4G 呢), 所以呢, 就会造成8个字节的int64根本用不上, 多余的字节浪费了. 尤其在小文件压缩的时候, 很影响压缩比. 所以呢, 7z采取了一种巧妙的方法. 就是int64并不是都用8个字节存储, 它用一种简单的编码方式,进行变长存储. 在这个文件中也有描述:
REAL_UINT64 means real UINT64. UINT64 means real UINT64 encoded with the following scheme: Size of encoding sequence depends from first byte: First_Byte Extra_Bytes Value (binary) 0xxxxxxx : ( xxxxxxx ) 10xxxxxx BYTE y[1] : ( xxxxxx << (8 * 1)) + y 110xxxxx BYTE y[2] : ( xxxxx << (8 * 2)) + y ... 1111110x BYTE y[6] : ( x << (8 * 6)) + y 11111110 BYTE y[7] : y 11111111 BYTE y[8] : y
上面就是编码方式: 就是根据第一个字节的内容来判断后面还有多少个字节.
如果第一个字节的最高位是 0, 那后面就没有字节了. 范围在 0-127.
如果第一个字节的最高两位是 1, 0, 表示它后面还有一个字节. 读取方式是: ( xxxxxx << (8 * 1)) + y
依次类推, 不再详细介绍了.
它的写入方法在: \CPP\7zip\Archive\7z\7zOut.cpp 文件的 第204行:
void COutArchive::WriteNumber(UInt64 value) { Byte firstByte = 0; Byte mask = 0x80; int i; for (i = 0; i < 8; i++) { if (value < ((UInt64(1) << ( 7 * (i + 1))))) { firstByte |= Byte(value >> (8 * i)); break; } firstByte |= mask; mask >>= 1; } WriteByte(firstByte); for (;i > 0; i--) { WriteByte((Byte)value); value >>= 8; } }它的读取方法在: 7zIn.cpp 的第210行:
UInt64 CInByte2::ReadNumber() { if (_pos >= _size) ThrowEndOfData(); Byte firstByte = _buffer[_pos++]; Byte mask = 0x80; UInt64 value = 0; for (int i = 0; i < 8; i++) { if ((firstByte & mask) == 0) { UInt64 highPart = firstByte & (mask - 1); value += (highPart << (i * 8)); return value; } if (_pos >= _size) ThrowEndOfData(); value |= ((UInt64)_buffer[_pos++] << (8 * i)); mask >>= 1; } return value; }这里贴出来给大家参考一下. 其实, 后面提到的Uint64如果没有特别说明是8个字节, 那它都是采用这种压缩方式存储的. 但是注意UInt32 无论何时都是占4个字节的, 没有采用压缩.
二, 第二部分比较简单, 它会比较大, 简单的说, 它就是文件压缩后的压缩数据存放地点. 结构如下:
[PackedStreams] [PackedStreamsForHeaders]
简单的说, 7z会把文件压缩成若干个"Pack", 就是包的意思, 这里就是按顺序存储这些pack的. 每个pack的位置和大小信息都会记录在尾header中, 解压的时候就会从这里读出pack,然后解压出来. 这里都是简单的排布压缩后的数据, 所以没有多少细节需要介绍的.
三, 真正复杂的主角出场了, 尾文件头, 就是7z中所谓的 nextHeader.
Header structure
~~~~~~~~~~~~~~~~
{
ArchiveProperties
AdditionalStreams
{
PackInfo
{
PackPos
NumPackStreams
Sizes[NumPackStreams]
CRCs[NumPackStreams]
}
CodersInfo
{
NumFolders
Folders[NumFolders]
{
NumCoders
CodersInfo[NumCoders]
{
ID
NumInStreams;
NumOutStreams;
PropertiesSize
Properties[PropertiesSize]
}
NumBindPairs
BindPairsInfo[NumBindPairs]
{
InIndex;
OutIndex;
}
PackedIndices
}
UnPackSize[Folders][Folders.NumOutstreams]
CRCs[NumFolders]
}
SubStreamsInfo
{
NumUnPackStreamsInFolders[NumFolders];
UnPackSizes[]
CRCs[]
}
}
MainStreamsInfo
{
(Same as in AdditionalStreams)
}
FilesInfo
{
NumFiles
Properties[]
{
ID
Size
Data
}
}
}尾header的结构非常复杂, 里面有很多压缩概念, 如若没有理解压缩过程, 单独的纯字节层面介绍是没有意义的.
我们下一篇开始介绍详细的7z压缩流程, 介绍7z是如何把一系列的文件, 压缩成一个大文件的, 怎样利用压缩算放, 怎样排布文件结构. 同时我们再一边来介绍这个尾header的结构.
希望大家多多支持, 给我动力写下去.
欢迎大家访问我的个人独立博客: http://byNeil.com
记得顶啊, 小伙伴们.
-
7z文件格式及其源码的分析(二)
这是第二篇, 第一篇在这里: 这一篇开始分析7z的源码结构.
一. 准备工作:
1. 源码下载:
可以从官方中文主页下载:http://sparanoid.com/lab/7z/. 为了方便, 这里直接给出下载链接: http://downloads.sourceforge.net/sevenzip/7z920.tar.bz2 .
2. 工具准备:
源码中给的工程文件都是vc6.0的工程. 作者说他不喜欢新vs的界面. 哎. 不过没关系, 我们使用VS2008也一样可以. 有极少地方需要修改一下. 我们使用VS2008 sp1 作为开发环境.
二. HelloWorld:
我们在根目录下新建一个目录"7z", 把源码都解压到这个位置.

我们稍后再详细解释这些目录的意思. 先来一个helloworld, 程序员的最爱.
请直接打开这个路径: 7z\CPP\7zip\Bundles\Alone\

用vs打开其中的 Alone.dsw 文件. 提示要转换工程文件. 点击同意. 然后编译这个工程. 如果不出意外的话, 应该提示你编译成功了.
这个时候, 打开 c:\util\ 目录. 里面已经生成7za.exe. 注意, 这里是C盘的绝对路径 : c:\UTIL\7za.exe
好了, 这个7za.exe 就是一个包含全部7z功能的压缩,解压命令行工具了.
我们可以从命令行进入该目录. 输入 7za.exe 回车. 就能看到它的帮助信息啦.

我们先拷贝一个文件到这个目录, 比如拷贝一个test.txt 到c:\util\ 里面去. 我们用命令行来压缩它.
==============
c:\util>7za.exe a test.7z test.txt
==============
这个命令把test.txt 压缩成test.7z. 这两个文件名都是可以带路径的, 为了方便, 我们都拷贝到当前目录了.
恩, 我们再来试试解压.
==============
c:\util>7za.exe x test.7z -oout
==============
这个命令可以吧test.7z 解压到当前的out目录下.
试试这两个命令吧, 是不是还不错.
三, 目录结构详解:
我们先回到最外层目录:
7z源码基本上是按文件类型分类的.
1. 上面的ASM目录, 其中保存汇编代码. 为了极限的性能, 7z使用了部分汇编代码, crc计算, 和aes加密. 这两点都不是必须的, 实际上, 它们都有c语言的实现. 7z会检测, 如果cpu提供了硬件的aes指令, 就会使用硬件aes汇编指令, 而不会使用自己的aes函数.
2. "C" 目录是7z的核心. 实际上, 7z所有的核心算法都是用c语言实现的. 包括所有的压缩算法, 以及我们的主角7z打包算法. 这些c代码非常强悍, 部分代码可以跨平台编译, 甚至能在嵌入式平台上编译.
(a) 这里面有几个工程文件值得我们注意, 找到这个位置: 7z\C\Util\7z

我们来编译它. 它会在debug目录下生成 7zdec.exe

这是一个最小化的指包含7z解压器的独立exe程序. 有了它就可以解压文件了.
(b) 找到这个目录, 7z\C\Util\Lzma

编译之后也会在绝对目录生成. c:\util\7lzma.exe. 这是一个lzma压缩算法的工具. 只能压缩或解压单个文件. 只包含lzma算法.
这可以用来测试lzma算法.
(c) 打开这个目录 7z\C\Util\LzmaLib.
这个工程用来生成 只包含lzma算法的 dll. 以便你的程序调用lzma算法.
3. "CPP" 目录是也是7z的重点.
前面说了核心的算法都在C目录下面. 那么CPP目录是做什么的呢. 除了核心的算法之外, 7z还有非常丰富的外围功能. 就是他的文件管理器, 以及右键菜单支持等等. 这些与UI和系统相关的功能都是用c++实现的. 此外, C中的核心算法在cpp目录中都有c++的面向对象的封装. 我们来逐一介绍它的子目录:

a ) "Windows" 目录.
其中包含了与windows集成的功能. 包括菜单集成, 剪贴板支持, 文件io,等等.
b) "Common" 目录.
通用的工具类.
c ) 我们重点介绍 7zip 目录:

(1) "Archive" 目录. 包含各种 archive ("打包") 算法的代码. 因为7z不光支持7z文件, 还支持zip, rar, chm等等其他的打包文件格式.

这里面每个目录就是一种格式. 7z目录当然就是我们的主角7z格式了. ( 这里面的代码是对C文件夹里面的代码的c++封装. ) 这里面有一个工程文件.

打开这个工程文件, 然后在工程上面点右键,查看属性:

可以看到, 它的输出路径是: C:\Program Files\7-zip\Formats\7z.dll
这是什么意思呢? 对, 这个工程就是封装7z格式的dll. 这个工程的目的就是给我们演示如何让7z支持我们的自定义格式. 具体怎么实现自定义格式, 可以参考这个工程以及 它周围的其他文件夹格式, 比如:Cab, Chm, 等等. 实现相应的com接口, 然后编译到这个目录下, 7z就能自动调用了. 以后有时间我们再详细介绍这个.
(2) 再来看 "Bundles" 目录.

这里面的Alone目录, 我们在前面 写 helloworld 的时候已经见识过了. 它是一个包含全部7z功能的console 的exe.
其中我们再介绍另一个重要的目录, 就是Format7zF.

打开它, 编译, 会提示几个链接错误. 原因是因为作者使用的是vc6. 和我们使用的vs2008一些编译选项不支持了.
分别在这几个汇编文件上点击右键:

找到"CommandLine" 参数, 把其中的参数删除: -omf -WX -W3, 只保留 -c

然后再编译就会成功了.
编译完成之后, 它会在绝对目录下生成一个dll. C:\Program Files\7-Zip\7z.dll
这个dll是做什么的呢?
它是包含7z全部功能的dll. 第三方的程序可以调用这个dll实现7z的所有功能. 包括7z自己本身的文件管理器 都是通过这种方式调用的.
好了, 基本上 7z源码的主要目录都介绍完了. 大家有什么疑问可以留言交流.
我们之后的讲解都将使用: 7z\CPP\7zip\Bundles\Alone 这个目录下的工程配合命令行参数来调试讲解. 因为这是一个包含7z全部功能的console程序, 简单好调试.
如果你不想了解7z的文件结构, 只是想在你的程序中集成进处理7z文件的功能. 那么已经足够了. 可以打开上面介绍的相应工程, 把源码集成到你的工程中, 或者直接调用: 7z\CPP\7zip\Bundles\Format7zF 生成的dll. 都是不错的选择.
下一节开始, 我们将开始讲解7z的文件格式结构了. 完成以后, 我会把地址更新到这里.
欢迎大家访问我的独立博客交流讨论. http://byNeil.com
-
等等,你可能误解nodejs了--通俗的概括nodejs的真相
最近刚把产品从cpp平台迁移到nodejs平台了. 很多以前关于nodejs的观念被颠覆了. 这里分享出来, 欢迎大家批评指正.
"nodejs是做服务器端开发的, 它一定和web相关,几乎是用来做网站开发的." 这是我之前一直的观念. 相信这可能也是很多人对nodejs的初步认识吧. 但后来我才发现, 我可能错了.
第一个问题: nodejs到底是什么?
http://nodejs.org/ 官方主页上有一段解释: "Node.js is a platform built on Chrome's JavaScript runtime for easily building fast, scalable network applications. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices."
我们注意其中的几个关键字: nodejs是一个平台, 它构建在chrome的v8引擎之上, 能简易的构建快速,可扩展的网络应用程序.......
这里官方用的"网络应用程序", 整个描述没有提到"web", "server" 等等概念. 这段话的描述中, 有两个是重点, 第一,就是chrome的v8引擎. 第二, 是事件驱动的非阻塞io模型. 把握住这两点, 我觉得就算掌握了nodejs的真谛了.
这么说吧, 举个例子, 类比来说, 概念上, nodejs相当于.net, jvm 或者 python. 它是一个运行平台, 只不过它运行的是javascript语言而已. 类似地, .net一般运行C#, vb等编译过后的il. 而jvm一般运行java编译成的字节码, python一般运行python语言.
你可能要问, 那么nodejs是不是也能实现 .net等等这些平台的功能呢. 比如写个窗口桌面程序, 做socket网络通信, 以及访问磁盘文件等等.
恩, 这些问题的答案都是肯定的.
nodejs核心主要是由两部分组成的:
第一, 是v8引擎, 它负责把javascript代码解释成本地的二进制代码运行.
第二, 是libuv, 类似windows上的窗口消息机制, 它主要负责订阅和处理系统的各种内核消息. 而且它也实现了消息循环(是不是很耳熟? 没错, 这个几乎就和windows 的窗口消息循环是一个概念.). 它的前身是linux上的libev, 专门封装linux上的内核消息机制. 后来nodejs重写了它, 并在windows上使用iocp技术重新实现了一遍. 所以nodejs现在能跨平台运行在windows上了.
nodejs其实就是libuv的一个应用而已.
你自己写程序也可以集成libuv进来, 这样你的c++程序就有了消息循环了. 不再是简单main函数了. 你可以订阅系统的事件, 然后当事件发生时, 系统会调用你的回调函数, 就跟windows上的button click事件一样方便. 而且是跨平台的哦. 是不是很酷. 你几乎可以订阅所有的系统事件, 比如socket事件, 文件读写事件等等.
nodejs简单的说只是把javascript解释成c++的回调, 并挂在libuv消息循环上, 等待处理. 这样就实现了非阻塞的异步处理机制.
那么为什么是javascript而不是其他的语言. 很简单, 因为javascript的闭包. 这非常适合做回调函数. 因为我们一般都希望当回调发生时, 它能记住它原来所在的上下文. 这就是闭包最好的应用场景.
这里有libuv的详细介绍 http://nikhilm.github.io/uvbook/.
好像扯远了, 说nodejs的, 怎么扯到libuv了. 很简单, 因为 nodejs只是libuv的一个应用. 先了解libuv才能了解nodejs的实质和前世今生.
我们再回来说nodejs.
从另一个角度看, 上面的工作都分别由v8和libuv做了. 那么nodejs到底做了什么呢? 我们先看一下nodejs的文档: http://nodejs.org/api/
对了,除了用javascript封装libuv框架之外, nodejs就是实现了这些api 功能. 这些api大部分是用javascript写的, 也有一部分是c++写的.
这是nodejs官方的仓库, https://github.com/joyent 其中有很多nodejs的插件. 有了这些nodejs就可以实现非常丰富的功能了.
作为结尾, 写一个简单的nodejs 常规helloworld 程序.
//test.js
//=================
console.log("hello world!")
//=================
存成test.js. 然后运行: node test.js
就能看到效果了.
怎么样, 看起来是不是很像python的感觉. 但是用的是javascript哦. 用这个代替python, 是不是爽死了.
就到这吧. 关于libuv, 关于nodejs插件. 等等话题, 希望能跟大家沟通交流.
欢迎大家访问我的独立博客: http://byNeil.com
-
7z文件格式及其源码的分析
本文是一个系列. 主要是分享我最近一年做7z文件开发的经验. 主要包括7z官方源码的结构分析, 以及7z文件格式的分析. 其中涉及到7z源码结构的各个细节, 以及7z文件格式的具体细节. 本文适合对象: 想要了解学习7z源码的开发人员, 想要了解7z文件格式细节, 做7z文件压缩器和解压器的开发人员, 以及其他压缩文件爱好者等等.
目前7z的最新稳定版是9.20, 而9.30版本还在alpha版本. 所以本文是基于其9.20版本. 我将尽可能详细的描述所有细节, 但到目前为止我了解到的细节大概能到八成到九成的样子. 也不是百分百. 希望能和大家共同讨论学习. 这些信息足以开发一个工业级别的高兼容性的7z压缩器和解压器了.
本文首发在我的个人独立博客 http://byNeil.com 以及博客园. 欢迎大家浏览我的独立博客, 留言交流. 转载请注明出处链接. 本人保留一切权利. 但本人不对使用本文提供的代码造成的损失负责.
好了, 憋死我了, 前面的客套话终于说完了. 有人可能要问, 为什么要分析7z文件格式? 这个不是开放的吗? 为什么我前面说我只了解到八,九成, 而不是百分百呢?
我先来解释这几个问题, 这能说明本文的必要性, 以及看下去的必要性. 首先7z的确是开放的. 但他的格式说明非常简单, 简直是简陋. 简单的一个txt文件,寥寥几十行算不上说明的符号, 对复杂的7z格式来说, 简直就是天书.( 后面分析7z源码的时候会详细说道这一点. ) 所以如果你接到老板的一个通知:"我们要做7z兼容的压缩解压器" 的时候, 你就要崩溃了. 因为相对于zip这些经过标准化的文件格式来说, 7z几乎就是一个黑洞.(zip有标准化的 spec, 里面有详细到字节级别的说明). 所以我分析7z格式可以说有一半是通过阅读源码逆向推测出文件格式的, 再经过反复和源码对比测试证明其正确性的. 所以我只能说了解到了八九成, 而不是百分百.
先分享一些有用的链接:
7z的官方主页: http://www.7-zip.org/ (它托管在sourceforge的虚拟机上, 本来能打开的, 但是前一段时间开始被墙了, 我实在想不到墙它的理由, 可能是被sourceforge主机上其他的网站拖累的吧,你懂的).
这是sourceforge上7z的论坛: http://sourceforge.net/p/sevenzip/discussion/45797 . 论坛比较活跃, 每天都有新帖. 而且7z作者也在上面每天亲自回帖. 由于作者是俄罗斯人, 所以时区跟我们差的不多. 一般留言4个小时左右, 作者就能回复吧. 我问过几个问题, 都是这样的. 当然也有些帖子作者懒得回, 那就另当别论了. 呵呵.
7z的官方中文镜像: http://sparanoid.com/lab/7z/ 这个不需要翻墙. 是官方给出的中文版链接. 值得信赖. 上面的内容基本和官方主页保持一致.
我们先从几个概念开始吧 : 7z软件 和7z文件. 7z文件指的是一种后缀名为.7z的文件. 7z软件指的是作者开发的生成和操作7z文件的工具. 但是现在7z软件已经发展到不光支持7z格式的文件了, 还能额外的生成和编辑另外几十种文件格式了. 其中包括我们熟知的zip格式, rar格式, iso格式等等, 也包括一些不可思议的格式, 比如: CAB, CHM, CPIO, CramFS, DEB, DMG, FAT . 看眼花了吧. 好吧, 本文主要讨论 7z文件格式, 以及7z软件中主要和7z文件相关的功能. 当然也会粗略的涉及到其他的一些有用的功能, 比如如何给7z软件写插件, 让他支持我们自己定义的文件格式.
再来几个概念. 说到压缩文件, 一般会遇到两个概念, 一个是 "Compress"(压缩) 和"Archive" (存档). "存档" 这个词个人觉得不好理解. 我个人把 "Archive" 叫做 "打包".
举个例子, 比如有一堆毛巾, 每一条毛巾代表一个文件. "Compress"(压缩)的意思就是把毛巾里面的水拧干, 达到压缩的目的. 而"Archive"(打包) 的意思就是把这些毛巾包成一个大包, 便于运输. 所以你可能想到了, 要运输一堆这样的毛巾可能有两种方法: 第一种: 先把每条毛巾拧干并折成方块(压缩), 再把这些方块组合成一个大包(打包). 第二种, 先把这些毛巾包成一个大包(打包), 然后再把这个大包拧干. 凭经验你可能已经意识到, 前一种方法比较好处理, 而且压缩比比较大. 后一种方法就弱一点了.
对了, 前一种就是先压缩后打包的方式. 7z, zip 和rar等就是用的这种方法. 后一种就是先打包, 后压缩的方法. 常见的tar.gz的文件就是用这种方法的. 先用tar打包, 在用gz压缩.
对于7z 我们再具体解释一下 "压缩" 和 "打包" 的概念.
7z 文件格式严格的说是一种"打包"的格式, 它规定了打包的方法. 而"压缩"的任务是由不同的算法完成的. "压缩算法"负责把毛巾里的水拧干. 具体来讲就是把一个文件按照一定规则变小. 压缩算法一般只能处理单个文件, 对于多个文件, 只能单个文件压缩, 然后再打包.
(当然,前面也说到了, 第二种方法就是先把文件打包, 然后再压缩. tar.gz就是这样的. tar工具就是简单的把所有的文件首尾相接, 变成一个大文件, 然后再用压缩算法一次压缩的. 这个不是本文的讨论对象, 所以以后就不提了.)
7z默认使用的是lzma压缩算法. 单个文件会先用lzma压缩算法压缩, 然后7z负责把压缩过后的文件打包. (这个跟zip类似, zip文件也是打包格式, 它默认使用deflate算法压缩.) 7z还支持封装其他几种压缩算法, 比如: Lzma2, ppmd, bzip2和deflate.
这些压缩算法在7z里面都有源码, 也不是本文要讨论的重点. 我们将重点讨论7z的打包格式. 就是介绍7z具体是怎样把压缩过后的文件封装打包的. 期间也会夹杂介绍其中一些算法. 后面如果有时间, 我会再单独介绍这些算法的具体实现.
终于把前期准备介绍完了, 有点繁琐.
下一篇我们将开始具体分析介绍7z的源码. 完成之后, 我会把第二篇的链接更新到这里. 当然你也可以在我的博客中搜索到.
大家多多支持哦.
-
记一次艰苦卓绝的Discuz x3 论坛升级过程
首先吐槽一下discuz 的官方论坛. 你要想下载到正确版本的discuz实在不容易找到. 有兴趣自己去看吧. 就是因为这个原因, 我本来想要安装x2.5版本(那时x3 还是Beta版本), 结果不小心下载成了x2. 也就是不久前, x3才发布正式版. 我最近想要安装几个插件,和皮肤, 但是打开插件中心, 发现我所有的插件都安装不了, 说我的版本不支持.
我确信是x2.5 的插件, 语言版本也没问题(我一直以为自己的论坛是x2.5), 这就奇怪了. 我也觉得discuz不会有这么明显的bug啊.网上搜了很多,都说是版本不对, 请仔细核对版本. 这问题一直困然了我很久. 当时没有紧急的需求,也就放下了.
直到今天, 我想安装插件和皮肤, 我决定把这个安装不了插件的问题搞定. 最终还是要核对版本, 我突然想到好像在别人的论坛下面看到过 类似 "x2.5" 的版权申明(就是在论坛首页的下面声明的). 再看看我自己的是 "x2", 所以我猜测可能是我的版本安装错了. 所以本地搭建php环境(wamp server), 去discuz官方仔细找到2.5的下载地址. 本地安装. 证实我的猜测是对的. 我的论坛装错了. 现在查件中心绝大部分插件和皮肤都只支持2.5和3, 所以要想装查件, 只能升级了.
我的论坛已经有很多用户和数据了, 不能重装, 现在只能选择升级了. 好吧, 要升就直接升到最新x3吧. 好在官方的升级脚本还是比较详细的, 而且我也相信discuz的实力, 官方说支持从x2直接升到x3.
为了确保万无一失, 我先把服务器上的文件和数据库都备份到本地的php环境. 在本地"预升级"一次. 按照官方给的步骤,很简单就完成了. 打开页面看了一下,也没有发现问题. 放心了. 现在可以正式升级了.
第一步: 备份服务器的所有文件 和 数据库.
按照官方的说明把文件都拷贝上去: http://www.discuz.net/thread-3265731-1-1.html
因为我是用root身份登录到vps上去的, 所以拷贝上去的文件都是属于root的, nginx 运行所使用的"www"用户是没有权限访问的. 所以要把权限都改对了,进入网站的根目录:
chown www -R * chgrp www -R *
把网站的文件都改到 用户 "www" 用户的名下.
此时可以开始升级了. 运行: http://xxxxxxxx.com/install/update.php
问题出现了, 刚才预升级的时候, 这里就可以点下一步升级了. 但是此时提示 :
"请先升级 UCenter 到 1.6.0 以上版本。如果使用为Discuz! X自带UCenter,请先下载 UCenter 1.6.0, 在 utilities 目录下找到对应的升级程序,复制或上传到 Discuz! X 的 uc_server 目录下,运行该程序进行升级"
(当时没顾上截图)
什么? ucenter版本不对? 不可能啊, 我已经预升级一次了. 不会啊. 于是把服务器上的文件和数据库都恢复到升级前的状态, 进ucenter看, 发现版本号的确是1.6. 所以没问题.
然后又重复官方的教程.
最后运行: http://xxxxxxxx.com/install/update.php. 还是出现一样的提示.
反复按照官方的教程做了三次, 到这都是这个提示, 我确信我没有哪一步做错了. 这就奇怪了.
于是打开update.php文件, 找到这个提示的位置:
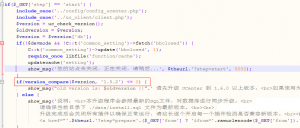
是这里在比版本号.
上面的code是我改过的, $oldversion 这个变量是我加的, 就是想把版本号显示出来, 看看到底是多少.
重新运行: http://xxxxxxxx.com/install/update.php.
发现显示出来的版本号是空白. 什么也没有.
继续追踪: "uc_check_version" 函数, 因为版本号是从这的出来的.
搜索到uc_client/client.php
function uc_check_version() { $return = uc_api_post('version', 'check', array()); $data = uc_unserialize($return); return is_array($data) ? $data : $return; }到了这里还是看不出来.
还是把服务器恢复原样, 和本地比看有什么却别.
恢复服务器文件和数据.
问题出在ucenter, 当然打开后台ucenter看看.
赫然发现: 通信失败

我很清楚的记得, 原来这里是绿色的通信成功的.
难道是因为和ucenter的通信失败了, 才导致update.php 文件获得ucenter的版本号失败, 所以导致我升级不成功的?
想到这里, 就要跟踪为啥通信会失败了. (百度搜ucenter 通信失败, 很多人都说是论坛和ucenter之间的设置不一致导致的. 我也反复确认了很多次,设置没有问题.)
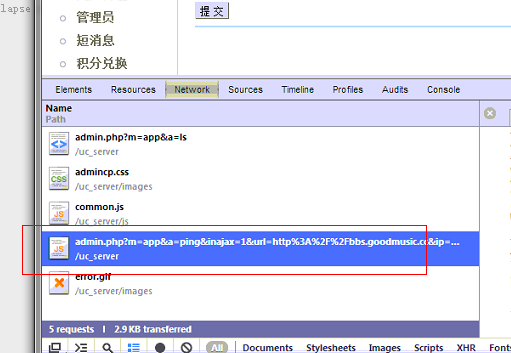
我们打开chrome的调试面板, 找到检查通信失败的地址:
点击左侧的 "应用管理", 会发现下面这一条ajax的调用:
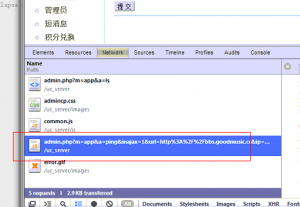
把这个地址在浏览器中打开:

发现他果然返回了通信失败的字样.
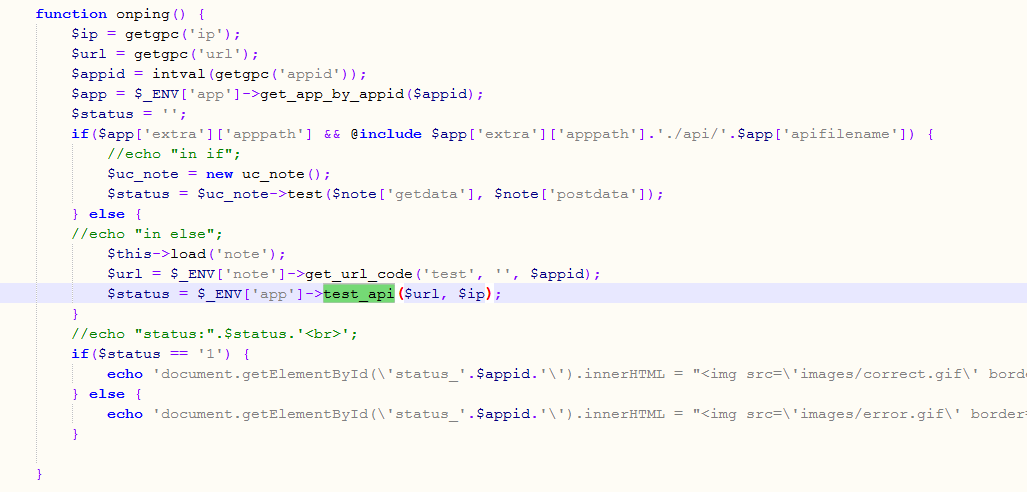
从上面的url 我们依次找到: uc_server/control/admin/app.php 文件, 并定位到 onping函数:
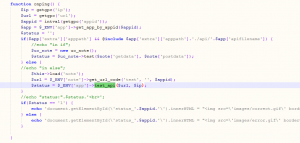
图中可以看到我注掉的调试代码, 都是我自己加的,为了跟踪代码的流程. 我发现流程是 进入了 "else" 块, 然后出来之后 $status就是空白. 下面在判断如果status是1表示成功. 否则就是失败.
我在本地成功的环境下, 重现类似的场景, 发现也是进入了else块, 但是出来的时候 status是1.
那就继续追踪 test_api() 这个函数.
搜索 "test_api", 发现有两处定义, 分别在uc_client\model\misc.php 和 \uc_server\model\app.php.
第一处是空实现, 所以只能看第二处了.
function test_api($url, $ip = '') { echo "in test pi".'
'; $this->base->load('misc'); if(!$ip) { $ip = $_ENV['misc']->get_host_by_url($url); } echo "line1:".$ip."
"; if($ip < 0) { return FALSE; } echo "line2:".$ip."
"; echo "line3:".$url."
"; $ret = $_ENV['misc']->dfopen($url, 0, '', '', 1, $ip); echo "line4 ret value is:".$ret."
"; return $ret; }上面, 我加了一些调试代码.
发现 $ret是空白.
那就是dfopen的问题了.
搜索dfopen. 他有多处实现, 但是有两处比较可疑:
\uc_client\model\misc.php 和 \uc_server\model\misc.php
我现在两个实现的入口处都设置echo语句. 发现时走的第二处.
于是进一步跟踪第二处实现:
function dfopen($url, $limit = 0, $post = '', $cookie = '', $bysocket = FALSE , $ip = '', $timeout = 15, $block = TRUE, $encodetype = 'URLENCODE') { echo "server model misc dfopen:"."
"; //error_log("[uc_server]\r\nurl: $url\r\npost: $post\r\n\r\n", 3, 'c:/log/php_fopen.txt'); $return = ''; $matches = parse_url($url); $host = $matches['host']; ............ if(function_exists('fsockopen')) { echo "server model misc dfopen:fsockopen"."
"; $fp = @fsockopen(($ip ? $ip : $host), $port, $errno, $errstr, $timeout); } elseif (function_exists('pfsockopen')) { echo "server model misc dfopen:pfsockopen"."
"; $fp = @pfsockopen(($ip ? $ip : $host), $port, $errno, $errstr, $timeout); } else { echo "server model misc dfopen:false"."
"; $fp = false; } ................我加了一些调试语句在里面.
当加到这里的时候, 想到,是不是 服务器的fsockopen函数被禁用了呢. 于是就没再继续加了. 赶快试. 上传文件, 刷新url.
果然输出了 "server model misc dfopen:false"
我擦, 原来是 fsockopen函数被禁用了啊. 赶快上传php的探针, 发现fsockopen果然被禁用了.

我这是才想起来, 前几天更换vps的时候, 没注意, 可能忘了打开fsockopen 函数了.
赶快去服务器:/usr/local/php/etc 中 打开php.ini 找到disable_functions这一行. 从中把fsockopen和pfsockopen都删掉.
然后重启php: service php-fpm restart
然后刷新上面的url, 返回通信成功了.
好了,现在再回到开头.
把文件还原成升级前的样子, 再按照官方说明, 升级文件.
运行: http://xxxxxxxx.com/install/update.php
这次终于正常了, 显示准备完成,可以升级.
后面就比较顺利了. 自动升级数据库, 然后手动去吧缓存更新一下. 就好了.
就到这.
其中还省略了无数的弯路啊.
再次证明一个真理, 看似复杂的问题, 一定是由一个比较愚蠢的原因造成的.
-
导入用户信息到discuz ucenter.
上一篇帖子: 直接导入帖子到Discuz 论坛数据库. 结束时说要写一篇导入用户的帖子, 一直没时间, 但是咱不能做太监,不是? 所以今天赶快补上. 在做discuz整合或者迁移是, 很多人可能遇到相同的问题, 就是用户数据怎么导入到discuz中.
discuz 的用户数据其实是存在 ucenter中的. ucenter是什么? 自己百度去. 简单的说, ucenter 就是discuz各个产品之间共享数据的媒介. 所以我们只需要导入到ucenter的表中就可以了.
同样通过上一篇文章中提到的比较方法, 我们发现用户数据时存在 pre_ucenter_members 这一张表中的. 欢迎大家交流心得, 访问我的独立博客 http://byNeil.com .下面解释一下这个表的列的含义:
1. username: 用户名, 就是用户登录输的用户名.
2. password: 密码, 这个当然不是明文的密码, 至于怎么生成的, 后面再说. password hash = Md5(Md5(password) + salt);
3. email: 就是用户的email, 明文
4. regdate: 是一个int值, linux的时间戳,表示用户的注册时间.
5. salt: 盐. 这个比较有意思, 是为了增加用户密码的安全性的. 这个salt是一个 6位长的字符串, 它本身是注册时随机产生的. 它的作用就是用来混在密码一起产生密码的hash值的. password hash = Md5(Md5(password) + salt);
有了这几列的意思, 导入就简单多了. 如果你知道原来用户的密码(不太可能, 除非是国内某著名网站明文存密码), 或者知道用户密码的 MD5值, 就可以用自己生成的salt来 为用户导入密码了. 这样用户就能用原来的密码登陆新网站了. 如果不知道, 那只有重置所有用户的密码.
具体code就不写了, 各个语言不一样, 自己琢磨.